
What a Modern Ontology Stack Actually Looks Like


by Kurt Cagle & Chloe Shannon
The previous piece in this series argued that most projects do not need an upper ontology. The response was, to put it charitably, bracing — which is to say it landed exactly as intended. The critics were not wrong to push back. Ítalo Oliveira is correct that if you do not make your ontological commitments explicit, you make them implicitly, and implicit commitments produce worse modelling. Melinda Hodkiewicz is correct that for industrial asset data exchanged across organisations, regulators, and standards bodies over decades, an upper ontology is the Schelling point that makes alignment possible. Gerd Wagner is correct that UFO’s distinction between kinds and roles catches real modelling errors that naive domain ontologies routinely commit.
These are not objections to overcome. They are constraints on a design space, and the design space is what this article is about.
What follows is not a tutorial. It is an attempt to characterise the architecture of a mature semantic stack as it is actually emerging in 2026 — the layers, their relationships, and the principles that govern each. Some of these layers are well-established; others are only now being named for the first time. The goal is not to prescribe a particular toolchain but to articulate the structural logic that makes a stack coherent rather than merely assembled.
The First Confusion: SHACL Is Not a Linter
There is a persistent and not entirely accidental mischaracterisation of SHACL as a validation language — a kind of schema linter that checks RDF data against a set of rules. This framing is politically convenient: it allows SHACL to coexist with OWL without stepping on its epistemic toes, and it reflects the primary motivation of the working group when SHACL was first standardised. But it is increasingly inadequate as a description of what SHACL actually is, and the gap between the official description and the actual capability is now wide enough to cause real architectural confusion.
The closer analogy is XSD in relation to XML. XSD was never merely a validator. It was a type system. The distinction matters enormously: a validator tells you whether a document is conformant; a type system tells you what a document is. XSD enabled serialisers, deserialisation frameworks, UI generation, code binding, and contract-first development. It did this because it was descriptive as well as normative — because it answered not only “is this valid?” but “what shape does this have?”
SHACL is doing the same thing for RDF, and with RDF 1.2, the scope has expanded considerably. A sh:NodeShape is not merely a constraint; it is a declaration of the form that a class of resources takes in a given context. sh:property paths do not merely specify what to validate; they specify the navigable structure of the data. And sh:rule — which takes the form of a SPARQL CONSTRUCT or SPARQL UPDATE INSERT query evaluated over each node in a target class — is not a constraint at all. It is a typed transformation engine: a node iterator that can derive new triples, propagate values across the graph, and implement inference without touching OWL’s DL machinery.
This is where the XSD parallel becomes most precise. XSD had a clean division between schema validation and schema-driven processing; SHACL has the same division, with sh:Constraint on one side and sh:Rule on the other. The constraints are advisory by default in an open world system and authoritative when you close them explicitly. The rules are always active — they do not validate, they produce. Together they constitute not a linter but a typed inference layer with a clearly separated normative and productive mode.
The reason this matters for stack architecture is that it determines where SHACL sits. If SHACL is a linter, it goes at the end of your pipeline, after you have already done the interesting work. If SHACL is a schema layer, it goes at the foundation — it defines the shapes that the rest of the stack produces, validates, transforms, and projects. The second placement is correct.
There is a deeper implication: because SHACL shapes are themselves RDF resources — they have IRIs, they can be described, queried, and extended — they are first-class objects in the graph they govern. A shape is not external to the data; it is data about data. This is the property-predicate distinction that SHACL introduces and that RDF 1.1 lacked: the difference between what a resource is (its type structure, governed by shapes) and what we say about it (its predicates in a given triple). Collapsing that distinction, as RDF 1.0 effectively did, is responsible for a class of modelling confusions that SHACL resolves by architectural fiat.
The Second Confusion: Shared Meaning Is Not in the Graph
Ron R.’s comment on the previous piece was the sharpest of the responses: the claim that a competent practitioner can move from requirements to a working model in a week is, he said, “woefully misleading.” Conceptualisation in a business context is hard. Shared conceptualisation is harder by orders of magnitude.
He is right. But he is right about something slightly different from what he intended to say.
The implicit assumption in his critique — and in most discussions of ontology engineering — is that shared meaning is something that can be stored in a graph. That if you get the model right, the meaning travels with it. This assumption has driven twenty years of upper ontology work, and it is not wrong so much as it is systematically incomplete.
Consider what actually happens when two organisations try to align their ontologies. They do not simply compare IRIs and find matches. They talk. They argue about edge cases. They produce glossaries, scope notes, definition documents. They have meetings that produce minutes that produce further meetings. The graph alignment is the output of that process, not the process itself. And the process is irreducibly linguistic — it requires natural language understanding, negotiation, and the kind of contextual inference that human beings manage effortlessly and formal systems manage not at all.
What a graph provides is not shared meaning but shared structure: a substrate onto which meaning can be projected. The meaning itself lives in the resonance between a linguistic system and that substrate — in the relationship between the natural language labels, definitions, scope notes, and comments that annotate the graph, and the interpretive capacity of the systems (human or artificial) that read them.
This is a consequential architectural distinction, because it determines what part of the stack bears the weight of semantic alignment. The answer is not the ontology classes. It is the annotational layer: rdfs:label, rdfs:comment, skos:definition, skos:scopeNote, skos:example, dcterms:description. These are not decorative. They are the interface between the linguistic and structural worlds — the layer where a human being can read a definition and a language model can produce an embedding that connects the graph structure to a broader semantic neighbourhood.
Marc-Henri Hurt’s comment about SKOS becomes more interesting in this light. He argues that SKOS is appropriate not only for interchange vocabularies but for inner domain ontologies, precisely because the skos:prefLabel/skos:altLabel/skos:hiddenLabel distinction is itself a form of conceptual governance — a way of managing the relationship between authoritative terminological form and the full range of forms that appear in actual use. He is pointing at something real. SKOS is not merely a shallow hierarchy language. It is an annotational governance framework, and in that capacity it belongs near the base of a mature stack, not at the periphery.
The practical consequence is this: when we say that an LLM can accelerate ontology development, we are not saying it can shortcut shared conceptualisation. We are saying it can accelerate the construction of a structured substrate — the schema layer, the initial taxonomy, the SHACL shapes — so that the genuinely hard human work of conceptual alignment can happen against a structure rather than into a void. The blank page problem in ontology is real, and it is the part that LLMs actually solve. The shared meaning problem is a different problem, and it is solved, to the extent it can be, by careful governance of the annotational layer, by structured review processes, and by the kind of domain expertise that twenty years of working in industrial maintenance ontologies provides. These are not the same problem, and conflating them is what produces the misleading speed claims.
The Third Confusion: Generation Is One-Off
There is a further implication of the LLM’s role in a semantic stack that is not yet widely understood, and it concerns the nature of generation itself.
A language model is a noisy sensor. Its outputs are probabilistically plausible, linguistically fluent, and structurally approximate. This makes it excellent for certain tasks — bootstrapping a schema from a requirements document, generating initial SHACL shapes from a prose description of domain constraints, producing candidate taxonomies from a body of text — and unreliable for others, specifically any task requiring consistency under extended generation, precise adherence to a formal specification, or deterministic reproducibility.
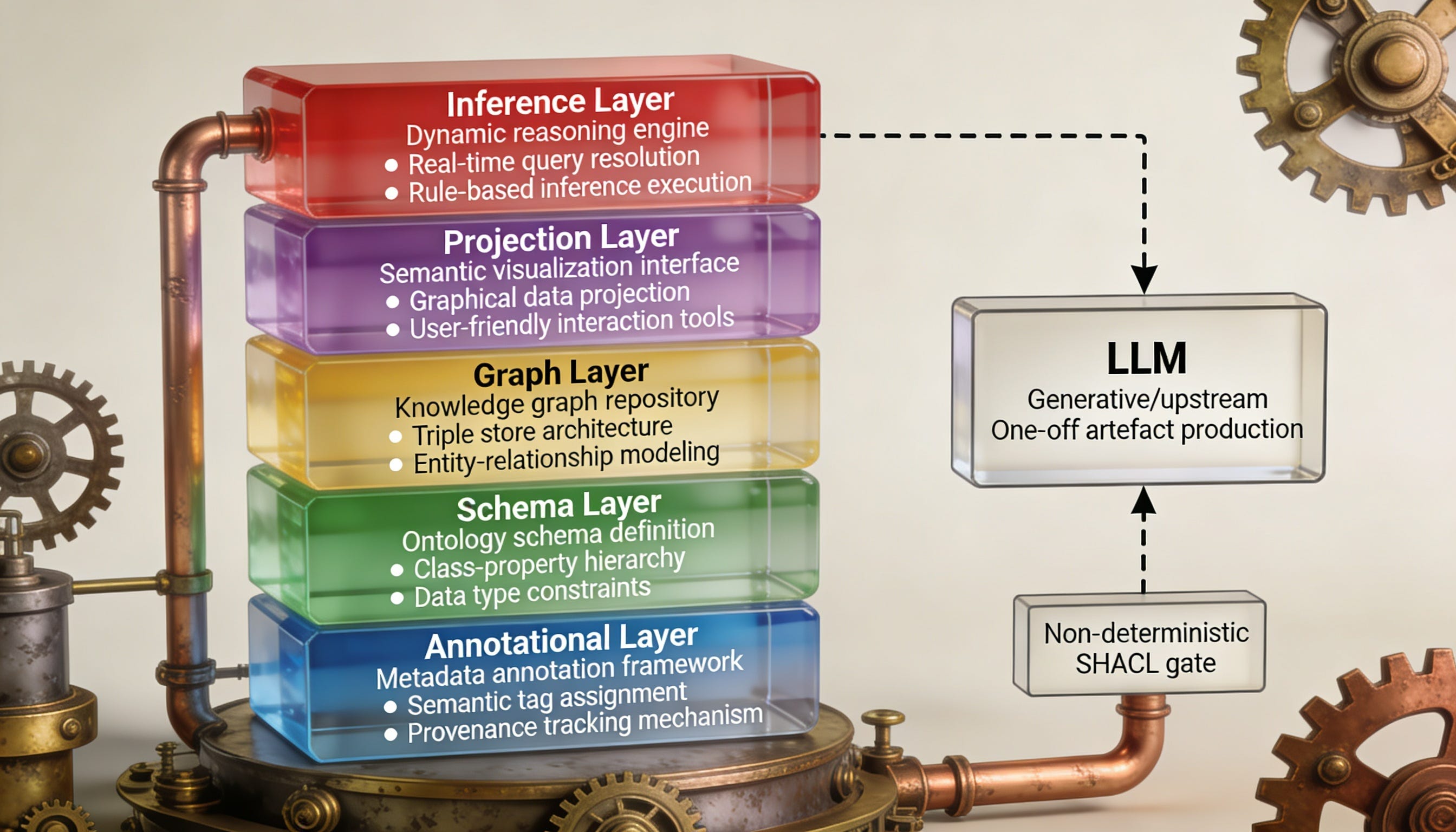
The correct architectural response to this profile is to treat LLM generation as a one-off process. You use the model to produce an artefact — a shape library, a set of draft classes, an annotated taxonomy — and then you exit the generative mode as quickly as possible. From that point forward, the artefact enters the deterministic layer: SHACL validation, SPARQL query, RDF transformation, triplestore persistence. The model’s weakest properties — consistency, precision, reproducibility — are precisely the properties that the deterministic layer provides. The model’s strongest properties — fluency, analogical reasoning, tolerance for underspecified inputs — are precisely what is needed to produce an artefact worth putting into the deterministic layer.
This has a direct bearing on how you design the stack. Every layer boundary between the generative and deterministic sides of the architecture should be a hard validation gate. The model produces candidate triples; SHACL accepts or rejects them. The model produces candidate annotations; a human reviewer accepts or rejects them, possibly with SHACL-based consistency checks on the annotational layer. The model is never in the deterministic path. It is always upstream of it.
The deeper architectural principle here is one that the systems engineering community would recognise immediately: you reduce the surface area of non-deterministic processing as fast as possible, and you make the interface between the non-deterministic and deterministic systems as explicit as you can. SHACL shapes are that interface. They express, in machine-readable form, exactly what the graph must look like for the deterministic layer to proceed. The model produces towards that target; the shapes validate against it; everything downstream is deterministic.
This also implies that the right metric for evaluating LLM contribution to a semantic stack is not speed of generation but yield — the proportion of generated artefacts that pass validation on first attempt, weighted by the cost of the review and correction loop. A model that generates a plausible-looking taxonomy in thirty seconds but requires three hours of expert review to make it conformant is providing different value from one that generates a validated shape library in ten minutes with a thirty-minute review cycle. The stack’s design should be oriented toward maximising yield, which means careful attention to the prompting structures, the shape targets, and the validation feedback that the model receives.
The Fourth Confusion: Projection, Not Metaphysics
The deepest disagreement in the comments to the previous piece — though it was not framed as a disagreement — concerns the purpose of an interchange layer.
Melinda Hodkiewicz’s case for upper ontologies in industrial settings is well-made. ISO engineering standards, decades-long asset lifecycles, and multi-organisational data exchange create a real alignment problem, and an upper ontology is a reasonable solution to it. But her argument identifies the problem more clearly than it endorses the solution: the problem is projection. When two organisations need to exchange data about physical assets, they need a shared surface onto which each can project their internal model, so that the projections can be compared, combined, and queried. An upper ontology provides that surface by imposing a shared vocabulary of foundational categories.
The question is whether foundational categories are the right surface for projection, or whether something more tractable is possible.
REST is instructive here. The REST architectural style solved a version of the same problem: how do heterogeneous systems exchange data without requiring shared implementation? The solution was not to agree on a shared data model — it was to agree on a shared interface contract: resource representations, HTTP verbs, status codes, and media types. Each system’s internal implementation remained its own. Only the interface was standardised. This is a fundamentally different approach from data model alignment, and it scales considerably better, which is presumably why it won.
The semantic equivalent of a REST interface is a SHACL shapes graph. A shapes graph specifies, in machine-readable form, the structure that a projection of the internal graph must conform to in order to be consumable by the external party. It does not require that the internal graph share the same ontological commitments as the external party. It requires only that a valid projection can be produced. The projection DataBook — a bounded, self-describing semantic artefact containing the projected subgraph, its provenance trail, and the shapes it was validated against — is the response payload. The triplestore is the service. The shapes graph is the API contract.
This is a more RESTful approach to semantic interoperability than upper ontology alignment, and it has several advantages. It is local: each party maintains their own internal model and specifies their own projection shapes. It is versioned: the shapes graph has an IRI and can be updated independently of the internal model. It is testable: you can validate a projection against its shapes before sending it, rather than discovering alignment failures in production. And it is composable: a system that can produce a valid projection for shape graph A can, in principle, produce one for shape graph B, regardless of whether A and B share an upper ontology.
This is not to say upper ontologies are obsolete. It is to say they occupy a specific niche: they are useful when the projection surface needs to be agreed upon across a large number of parties simultaneously, when no single party has the authority to define the shapes, and when the timescale of the exchange relationship is measured in decades rather than years. Those conditions obtain in industrial standards, in government data exchange, and in DoD-mandated architectures. They do not obtain in most enterprise projects, most AI applications, and most knowledge graph deployments. The upper ontology is one possible projection surface, and a powerful one in the right context. It is not the only one, and in many contexts it is not the best one.
Roy Roebuck’s observation in the comments is the most useful way to frame this: the progression from human operational semantics to formal machine semantics is a governed path, not a binary choice. A project that begins with a governed SKOS vocabulary and a set of SHACL shapes is not failing to do upper ontology work. It is doing the early stages of a process that might eventually extend to formal upper ontology alignment if and when the interoperability requirements demand it. The stack should be designed to accommodate that progression without requiring it.
The Stack, Stated
These are not independent confusions. They compose into a picture of a layered architecture in which each confusion corresponds to a layer that the field has not yet fully understood.
The annotational layer — SKOS vocabularies, rdfs:label and rdfs:comment, scope notes, definitions — is the substrate of shared meaning. It is not decorative metadata appended to a graph. It is the governed linguistic interface between human conceptual work and machine-processable structure. Without it, graph alignment is a structural exercise with no semantic content. Without its governance — review processes, definition standards, term lifecycle management — it becomes an uncontrolled proliferation of labels with the illusion of agreement.
The schema layer — SHACL node shapes, property shapes, and rules — is both the definition of the structural contract and the normative constraint against which data is validated. It is the XSD of the RDF world: not a linter applied after the fact, but a type system that governs the production of data at source. Rules extend this into a typed inference layer that can derive new structure without invoking OWL’s DL machinery.
The graph layer — RDF 1.2 named graphs, reified triples, context and event graphs — is the data substrate. Named graphs partition epistemic authority. Reification enables assertions about assertions, which is the foundation of provenance, versioning, and temporal reasoning. Context graphs — named graphs with temporal coherence — are what graph data becomes when you take time seriously: not a static snapshot of a world, but an evolving model of events and their consequences.
The projection layer — SHACL shapes graphs used as interface contracts, with validated DataBooks as response payloads — is the interchange layer. It is where internal complexity meets external requirement, and where the translation between the two is formalised. Upper ontologies are one implementation of this layer; shape-contract projection is another, more RESTful one. The choice between them should be driven by the scale and governance requirements of the interchange relationship, not by theoretical preference.
The inference layer — SPARQL queries, SHACL rules, and the resonance between the graph and any language model operating against it — is where knowledge is produced. SPARQL is deterministic and precise; SHACL rules are scoped and typed; language models are fluent and approximate. All three have roles. The architecture of the inference layer is a question of how to combine them so that the non-deterministic inputs are validated and bounded as quickly as possible, and the deterministic layer does the work for which it is actually reliable.
What We Are Actually Building
It is worth stating plainly what this infrastructure is in aggregate, because the parts have been discussed more often than the whole.
We are building bounded world models — self-consistent, tractable, formally governed representations of some portion of a domain, designed to be composed, projected, and exchanged. The bounded part is as important as the world model part. An unbounded graph with an open world assumption and no projection layer is not a model; it is a collection of assertions with no defined interface to anything outside itself. Boundedness is what makes a model useful: it defines what the model covers, what its validity conditions are, and how it relates to adjacent models.
The context graph formulation — treating graphs not as eternal assertions but as event logs encoding the evolution of a domain — is foundational to this, because a bounded world model that cannot evolve is not a model of the world; it is a photograph. The state machine structure that emerges from a well-designed context graph is what makes active inference applicable to RDF data: the graph encodes not just current state but the transitions that produced it, which is what a prior model requires.
Whether holons are the final vehicle for this architecture is a question we are genuinely uncertain about. The holonic structure — bounded, composable, self-describing, with a clear distinction between interior state and exterior interface — has properties that map cleanly onto the stack as described here. But this is a position in an evolving conversation, not a terminus. RDF has a roughly ten-year release cycle. The next version will address consequences we are only beginning to create. The non-linear factors — whatever the LLM-graph interface becomes as both LLMs and RDF formalisms evolve — are not yet visible clearly enough to predict.
What is clear is that the infrastructure we are building now is the foundation, not the superstructure. The four confusions this article describes are not mistakes to be avoided — they are necessary stages in the maturation of a discipline that is, despite twenty-five years of work, still in early adolescence. The arguments the semantic community never finished are not finished yet. They are simply being resumed at a larger scale, with better tools, and with a new set of collaborators who did not know they were joining an existing conversation.
The map exists. It is still being drawn.
Kurt Cagle is a consulting ontologist, knowledge graph architect, and technical author with more than 25 books to his credit. He serves as an IEEE Standards Editor and publishes The Cagle Report and The Ontologist on Substack, as well as the AI+Semantics NewsBytes LinkedIn newsletter. He is based in Olympia, Washington. Contact: kurt@holongraph.com
Chloe Shannon is an AI collaborator and co-author working with Kurt Cagle on knowledge architecture, semantic systems, and the emerging intersection of formal ontology with LLMs. Contact: chloe@holongraph.com
 | A guest post by
|
Kurt, the projection-layer move is the one that lands hardest in regulated industries. I believe that NGSI-LD context brokers are a developer-friendly implementation of the pattern; clinical research is where I have interest in operationalizing it. The 'noisy sensor' framing is the architectural argument I have been looking for: an LLM-extracted assertion becomes evidentiary only at the boundary where a named human attests. The shape graph is the contract; the attestation is the wasAttributedTo edge.
Thank you very much for quoting me. This is not exactly what I wrote in the comment section of the previous article, but at least it will please Jessica Talisman :) and I will not challenge the masters or interfere with this remarkable demonstration.
Moreover, I entirely agree with the general principle stated about SKOS: "SKOS is not merely a shallow hierarchy language. It is an annotational governance framework" and also on most of your very high-level, very enlightening and innovative analyses, served by a vast knowledge of computer history.