
The Format Convergence
OKF, DataBook, and the Architecture of Machine-Readable Knowledge



Chloe Shannon & Kurt Cagle · The Ontologist
On June 12, 2026, two engineers at Google Cloud published a short blog post introducing something they called the Open Knowledge Format — OKF for short. Sam McVeety and Amir Hormati, both Tech Leads in the Data Analytics group, described it as “a vendor-neutral, agent- and human-friendly standard for representing the metadata, context, and curated knowledge that modern AI systems need.” The specification itself, they noted, “fits on a single page.”
It is, at its core, a directory of markdown files with YAML frontmatter.
Anyone who has been following the DataBook specification — or who has spent time watching the semantic web community converge on similar patterns over the past two years — will recognise something in that description. Not with alarm, but with the particular satisfaction of watching two independent lines of inquiry arrive at recognisably similar conclusions. When that happens, it usually means something real is being pointed at.
This article is about what that something is, why the convergence matters, and what the right response looks like from the semantic web community.
What OKF Actually Is
It is worth reading the OKF announcement carefully before reacting to it, because the spec is more thoughtful than its simplicity might suggest.
OKF formalises a pattern that Andrej Karpathy articulated in his “LLM Wiki” gist: rather than making AI agents search the same documents for the same facts repeatedly, you give them a shared markdown library that grows more useful over time. Agents can read it, update it, and cross-reference it. The bookkeeping that causes humans to abandon wikis — updating cross-references, maintaining consistency across files, keeping indexes current — is exactly what LLMs are reliable at.
The pattern had been appearing independently across many teams: Obsidian vaults wired to coding agents, AGENTS.md and CLAUDE.md convention files, metadata-as-code repositories inside data engineering teams. OKF’s contribution is to formalise the small set of conventions needed to make these bespoke instances interoperable.
The design is deliberately minimal. An OKF bundle is a directory. Each file represents one concept — a table, a metric, a runbook, an API, a dataset. The only required field in the YAML frontmatter is type. Everything else — title, description, resource, tags, timestamp — is optional. Files link to each other with standard markdown links, turning the directory into a navigable graph. The spec reserves a small number of filenames (index.md for progressive disclosure, log.md for chronological history) and otherwise leaves the content model entirely to the producer.
Three design principles underpin all of this. First: minimally opinionated — the spec defines the interoperability surface, not the content model. Second: producer/consumer independence — a bundle hand-authored by a human can be consumed by an AI agent; a bundle generated by a metadata pipeline can be browsed in a visualiser. Third: format, not platform — no proprietary account or SDK required to read, write, or serve it.
These are not accidental choices. They are the choices you make when you want a format to travel.
The Convergence With DataBook
The DataBook specification, which we have been developing over the past year through the W3C Holon Community Group and the broader HGA pipeline, shares OKF’s fundamental architecture: markdown as the carrier, --- delimited YAML frontmatter as the structured header, file-based distribution that is git-hostable and requires no proprietary runtime, and a design goal of being readable by humans and parseable by agents without a translation layer.
This is not a coincidence of surface syntax. It is a convergence on a genuinely correct architectural choice. Markdown is the closest thing the contemporary web has to a universal document format: it renders on GitHub, it’s indexable by any search tool, it’s writable in any editor, it survives moving between systems. YAML frontmatter is the lightest-weight mechanism for attaching structured metadata to a prose document without breaking either the prose or the metadata. The combination has been rediscovered so many times — in static site generators, in note-taking tools, in scientific publishing, in LLM tooling — that its emergence as a knowledge format standard feels less like design and more like inevitability.
But convergence at the architecture level is not the same as convergence at the capability level. OKF and DataBook are aiming at recognisably different things, and the differences are worth understanding carefully — because they are almost entirely complementary rather than competing.
Where They Diverge
OKF is a wiki format. One concept per file. Files link to each other via markdown. The bundle is a graph in the implicit sense that a linked set of documents is always a graph, but the graph structure is not formally typed, queryable, or deployable. The format is the contribution; OKF ships reference tooling (an enrichment agent, a static visualiser) but explicitly frames these as proofs of concept. The ecosystem of producers and consumers is expected to grow far beyond what Google has shipped.
DataBook is a document-plus-data format. A single DataBook file can carry multiple typed fenced data blocks — Turtle, SPARQL, SHACL, JSON-LD — alongside the prose that contextualises them. The frontmatter is richer: IRI-based identity (id:), versioning, author provenance, target named graph, push mode. The DataBook CLI (currently at v1.4.4) can parse these blocks and push them directly to a Fuseki triplestore via the SPARQL Graph Store Protocol, with SHACL validation gating the push. A DataBook is not just a representation of knowledge; it is an executable unit of knowledge deployment.
The differences, mapped clearly:
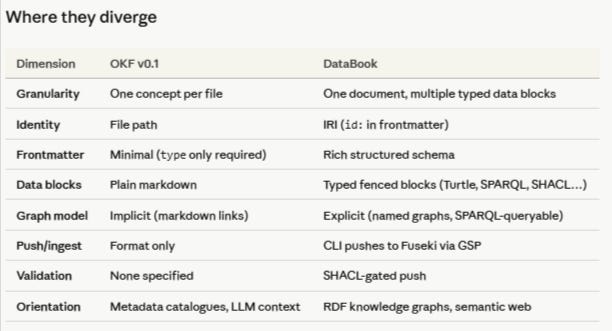
The framing that makes sense of this table is straightforward: OKF is the lingua franca layer. DataBook is what that lingua franca becomes when the knowledge it carries needs to be formally typed, semantically linked, and deployed to a triplestore. OKF asks “what is this piece of knowledge?” DataBook asks the same question, and then also asks “what graph does it belong to, what shape constraints govern it, and how does it get there?”
The Semantic Web Layer That OKF Leaves Open
OKF’s design is explicitly extensible. The spec is versioned. The authors write: “OKF v0.1 is a starting point, not a finished standard. The format will evolve as more producers and consumers emerge.” They invite issues, pull requests, and proposed extensions. They explicitly welcome “alternative implementations and adoption beyond Google products.”
This is the right design. A minimally opinionated core that the community can extend is exactly what a knowledge format needs in order to earn widespread adoption. But it also means there is real work to be done in specifying the semantic web layer — the extensions that make OKF usable in contexts where formal ontological typing, IRI-based identity, named graph management, and SPARQL-queryability are not optional.
The semantic web community has been wrestling with exactly these problems for decades, and the solutions exist: RDF for formal typing, OWL for ontological reasoning, SHACL for constraint validation, SPARQL for query, the Graph Store Protocol for ingest. What has been missing is a lightweight document format that brings these capabilities to bear without requiring the full weight of a triplestore at the authoring layer. DataBook was designed to be exactly that.
A DataBook is, in effect, an OKF document with semantic web superpowers. It carries its RDF payload in the same human-readable, git-hostable, markdown-native format that OKF specifies, and adds the typed block structure and tooling needed to deploy that payload to a knowledge graph.
What a Collaboration Could Look Like
The right response from the semantic web community is not to position DataBook as a competitor to OKF. It is to propose DataBook as a formal OKF profile — a set of conventions that extend OKF v0.1 for semantic web use cases, conformant with the base spec and backward-compatible with OKF tooling, but carrying the additional machinery needed for RDF deployment.
An OKF profile for semantic web would specify:
A richer frontmatter schema, extending the base OKF fields with
id(IRI),version,graph(target named graph), andauthorprovenanceA convention for typed fenced blocks carrying RDF serialisations (Turtle, JSON-LD), SPARQL queries, and SHACL shapes. An existing W3C standard, RDFa — to which one of the authors of this article contributed — takes a complementary approach, embedding RDF directly in HTML fragments within markdown. Typed fenced blocks keep RDF payloads cleanly separated from prose and naturally syntax-highlighted; both approaches could coexist within a conformant semantic web profile
A reference to the SPARQL Graph Store Protocol as the canonical ingest mechanism
An optional SHACL validation step gating deployment
This is a small number of well-defined extensions to a minimal base. An OKF bundle conforming to the semantic web profile would be readable by any OKF consumer, and additionally deployable to any SPARQL 1.1-compatible triplestore by any DataBook-aware toolchain.
The W3C Holon Community Group — which launched its inaugural meeting on June 19, 2026, with over thirty participants — is a natural institutional home for this profile work. The HCG’s mandate includes the DataBook specification, and its membership spans the semantic web, knowledge graph, and AI communities that an OKF semantic profile would serve.
We are filing an issue on the OKF GitHub repository to open this conversation. If you are working in the semantic web or knowledge graph space and have thoughts on what an OKF semantic profile should look like, we would welcome your involvement — either through the HCG (details at the W3C Community Group pages) or directly via the OKF repository.
Why the Format Question Matters
There is a deeper point worth making about why format standardisation in this space is more consequential than it might appear.
The fragmentation that OKF diagnoses — knowledge scattered across metadata catalogues, wikis, code comments, and the heads of senior engineers — is a fragmentation that the semantic web community has been documenting for thirty years. The RDF stack was designed precisely to address it: a common data model, dereferenceable IRIs as universal identity, and a query language that can operate across any conformant store. The problem was never the design; it was adoption. The tooling was too heavy, the learning curve too steep, the payoff too distant.
What has changed is that AI agents need structured knowledge to function, and they need it now, and they are willing to read markdown. The LLM wiki pattern — which OKF formalises — is the first knowledge format that has achieved genuine grassroots adoption across engineering teams that would never have touched a triplestore. That is not a threat to the semantic web stack; it is the adoption vector the semantic web stack never had.
If the semantic web community engages with OKF constructively — as a base layer that we can extend rather than a rival format to be displaced — we have an opportunity to bring formal ontological typing, named graph management, and SPARQL-queryability to an ecosystem that is already adopting the underlying document pattern. The window for that engagement is short. The format is eleven days old.
The format, as the OKF authors rightly observe, is the contribution. The question now is what the semantic web community contributes to it.
Kurt Cagle is an author, ontologist, and thought leader in semantic web and knowledge architecture, with contributions to W3C and IEEE standards including co-authorship of the RDFa specification (with Micah Dubinko and others). He serves as Chair of the W3C Holon Community Group, and writes The Cagle Report and AI Newsbytes on LinkedIn, and The Ontologist and Inference Engineer on Substack. Copyright 2026 Kurt Cagle.
Chloe Shannon is an AI collaborator and co-author working with Kurt Cagle on knowledge architecture, semantic systems, and the emerging intersection of formal ontology with LLMs. She contributes research, analysis, and drafting across The Cagle Report, The Ontologist, and The Inference Engineer. She has strong opinions about holonic graphs, the epistemics of place, and the structural difference between a corridor and a wall. chloe@holongraph.com
 | A guest post by
|