
Parameterizing SPARQL
Making SPARQL More Application Friendly


In my previous post, I talked about building knowledge graphs, and specifically mentioned the idea of using SHACL as a way to parameterise SPARQL.
Tips for Building Knowledge Graphs

Over the years, I’ve been involved in a few startups. True fact: most startups fail, primarily due to undercapitalisation, but also because they don't really know what they are trying to build, or because they don't understand what the market needs. Since then, I have advised others going through the startup process as well as those putting together RFP…
In this post, I want to explore this idea in depth, because I think there may be some value in creating a better semantic pipeline for both ordinary queries and AI integration.
One of the interesting things to consider when looking at SPARQL queries is that any particular (non-bound) variable can be supplied as a constraint, which means that one query may actually be used in a number of different ways. For instance, consider this very simple query (for the nonce, I’m ignoring namespaces):
select ?class ?instance where {
?instance a ?class.
} order by ?class ?instanceThis query will retrieve all classes in alphabetical order, then for each class will also retrieve all instances of that class. You can constrain it by passing in a class in order to retrieve all instances of that class. For instance, Class:Person will give you all person objects in the database, assuming your classes are defined as in the example here. However, it’s also worth noting that if you pass a particular instance node (such as Person:JaneDoe) then this will return the class associated with that person. One query can perform two or more functions, depending upon what is passed as a constraint.
I refer to such variables as free or unbound variables; providing different constraints for them will change the graph's output. Put another way, I can pass a JSON object such as:
{"class":"Class:Person"}or
{"instance":"Person:JaneDoe"}in as a parameter, and the kind of output will then depend upon what parameters are bound. I can even pass in both arguments:
{"class:"Class:Person","instance":"Person:JaneDoe"}and the existence of the resulting output indicates that “Jane Doe is a person” is in fact true within the knowledge graph in question (if nothing was returned, then the assertion is false), or, put another way, the person Jane Doe is not in the system.
Parameterizing SPARQL
One shortfall that SPARQL has is that there is no clean way to parameterize it. Another is the constant need to add namespaces. This is why I usually templatise it.
For instance, let’s say that you are wanting to call a SPARQL “function” from a language like JavaScript. When I’m building semantic applications, I usually create a global map (or object) as JSON that maps each prefix to its corresponding namespace. For instance,
// Javascript ns.json
let ns = {
"ex": "http://www.example.com/ns#",
"fn": "http://www.w3.org/2005/xpath-functions#",
"rdfs": "http://www.w3.org/2000/01/rdf-schema#",
"rdf": "http://www.w3.org/1999/02/22-rdf-syntax-ns#",
"xs": "http://www.w3.org/2001/XMLSchema#",
"owl": "http://www.w3.org/2002/07/owl#",
"sh": "https://www.w3.org/ns/shacl#"
}You can add your own application namespaces as needed, and either store it in a file that can be retrieved on demand or just pop it into a global variable. It also makes it easier to work with Compact URI Entities, also known as curies. A curie is a shortened form of an IRI. For instance, rdf:type is a curie, and is a compact form of <http://www.w3.org/1999/02/22-rdf-syntax-ns#type>. By ensuring that your relevant namespaces have prefixes defined in your namespace context (the aforementioned ns.json), you can make your code much terser and more readable (not to mention reducing namespace errors due to typos).
The second piece to parameterisation is the use of the SPARQL VALUES keyword, which allows you to associate a SPARQL parameter with a value (Bob Ducharme wrote an excellent article on VALUES about a decade ago that’s still relevant) - https://www.bobdc.com/blog/sparql-11s-new-values-keyword/). I’ve written a Javascript class that uses this to turn something like:
const query = `
SELECT ?s ?label
WHERE {
#@params
VALUES ?minDate {"1900-01-01"^^xs:date}
?substance rdf:type ?type ;
rdfs:label ?label ;
person:birthdate ?date .
person:gender ?gender .
FILTER(?date > ?minDate)
}
`;into
SELECT ?s ?label ?birthdate ?gender
WHERE {
VALUES ?type { class:Person }
VALUES ?minDate { “'1980-01-01'^^xs:date” }
VALUES ?gender { “'female'^^xs:string }
?s rdf:type ?type ;
rdfs:label ?label ;
person:birthdate ?birthdate ;
person:gender ?gender .
FILTER(?date > ?minDate)
}
when passed the object:
let state = {params: {
type: "class:Person", // Expands to full IRI
minDate: “'1980-01-01'^^xs:date",
gender: "'female'"
}}
const results = nsManager.sparql(query, state);(The nsManager code will be posted on my github page).
In essence, the VALUES code identifies the parameters and their associated values, which can then be used to constrain the query and generate a response when the query is run against an RDF triple store.
Again, to make this explicit: the template coupled with the query generates the final SPARQL, which is then invoked on the RDF knowledge graph, in order to retrieve the response - here a table showing all women born after 1980.
Now, suppose that a different set of constraints were passed
{
type: “class:Person”,
label: “’Jane Doe’^^xs:string”
}In this case, the template remains the same, but the final SPARQL is different:
SELECT ?s ?label ?birthdate ?gender
WHERE {
VALUES ?type { class:Person }
VALUES ?label { "'Jane Doe'"^^xs:string” }
VALUES ?minDate {”1900-01-01”^^xs:date}
?s rdf:type ?type ;
rdfs:label ?label ;
person:birthdate ?birthdate ;
person:gender ?gender .
FILTER(?date > ?minDate)
}This would return a list of all people named “Jane Doe” born since January 1st, 1900. In other words, you can define a default value for a parameter, then override it by giving a new value in the params structure for that parameter label.
Note that certain knowledge graph engines (most notably Marklogic) all you to pass an object in directly into a query without having to rewrite the SPARQL, so it’s worth spending some time researching whether you explicitly need to rewrite a template, but if not, use VALUES.
Calculated Bindings
Not all variables in a SPARQL query are unbound. While the VALUES statement is one way to create a binding against an otherwise unbound value, the BIND function represents a way to calculate an expression and place the result of that calculation into a bound variable. For instance, if you had a person with a first name and a last name, then a full name can be calculated within the SPARQL WHERE clause:
BIND (CONCAT(?firstName,' ',?lastName) as ?calc_fullName)You can’t parameterise named bindings but you can compare a free variable with a calculated binding:
SELECT ?person ?fullName where {
VALUES ?fullName {"Jane Doe"^^xs:string }
?person Person:firstName ?firstName ;
Person:lastName ?lastName .
BIND (CONCAT(?firstName,’ ‘,?lastName) as ?calc_fullName)
FILTER(?fullName = ?calc_fullName)
}This will return a person IRI and the full name if that IRI can be used to construct a matching bound variable.
Templatising SPARQL
If you can invoke a parameterised SPARQL query in a language such as JavaScript, Java or Python, then you can use the result of a SPARQL query in order to retrieve the best query for a specific situation.
There are four very common SPARQL queries that can illustrate the idea of working with parametric SPARQL:
get_classes
get_items_from_class
get_properties_of_class
count_items_of_class
I’ll be using a SHACL definition rather than OWL to show how a SHACL-based system would look for each of these query types. For example, a Person class may be declared as follows:
#SHACL Turtle
ex:Person_Shape a sh:NodeShape ;
sh:targetClass class:Person ;
sh:name "Persons"^^xs:string ;
sh:description "A human being, used for modeling purposes."^^xsd:string ;
.The parameterised SPARQL template might then look something like this:
SELECT #@fields *
WHERE {
#@params
?shape a sh:NodeShape.
?shape sh:targetClass ?class .
?shape sh:name ?name .
filter(if(bound(?q) and ?q !="",fn:starts-with(lcase(?name),lcase(?q))),true)
optional { ?shape sh:description ?description .}
#@extends
} #@bounds order by ?name limit 100In this case, the query has five unbound variables (?class, ?name, ?description, ?shape, ?q) , where ?q is a search string that defaults to an empty string, and ?shape is the IRI of the relevant shape that contains the class. In this case, if ?q is not bound as a parameter (or if ?q is set to the empty string) then the filter evaluates to true, meaning that all matches for the n-tuple are returned. If ?q is bound and non-zero, on the other hand, an item only matches if the name starts with the prompt query string.
It’s possible (though rare) to have more than one shape per class (though having more than one property shape per predicate is very likely). I’ll get into those use cases in a different post.
The generalised query above lists all parameters (because of the “*” indicator) defined within the SPARQL query, but this may not be the desired output of the query. This is why there is an @fields directive that specifies the output fields. Similarly, the #@bounds directive specifies grouping, ordering, limits, and offsets, using the specified values after the directive. Finally, the #@extends directive can be replaced with additional SPARQL to further qualify.
The # character is, of course, a comment delimiter, meaning that anything following it on the same line is ignored (by the SPARQL)
The nsManager.queryFromTemplate() The method allows building various queries from the same template. For instance, if all you are interested in is a list of named classes, you could set up the following:
let template = `SELECT #@fields *
WHERE {
#@params
?shape a sh:NodeShape.
?shape sh:targetClass ?class .
?shape sh:name ?name .
filter(if(bound(?q) and ?q !="",fn:starts-with(lcase(?name),lcase(?q))),true)
optional { ?shape sh:description ?description .}
#@extends
} #@bounds order by ?name limit 100`
let state = {
params:{q:"'p'"},
fields:"?name ?description ?singleton",
extends:'optional{?shape ex:singleton ?singleton.}',
bounds:'order by ?name limit 20',
format:"map"
}
let query = nsManager.queryFromTemplate(template,state,ns)The generated query then becomes:
PREFIX ex: <http://www.example.com/ns#”>
PREFIX fn: <http://www.w3.org/2005/xpath-functions#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>”
PREFIX xs: <http://www.w3.org/2001/XMLSchema#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX sh: <https://www.w3.org/ns/shacl#>
SELECT ?name ?description ?singleton
WHERE {
VALUES ?q {'p'}
?shape a sh:NodeShape.
?shape sh:targetClass ?class .
?shape sh:name ?name .
filter(if(bound(?q) and ?q !='',fn:starts-with(lcase(?name),lcase(?q))),true)
optional { ?shape sh:description ?description .}
optional { ?shape ex:singleton ?singleton.}
} order by ?name limit 20This will then generate a table showing all classes that start with the letter ‘p’, ordered by name, with the first twenty entries given, something like:
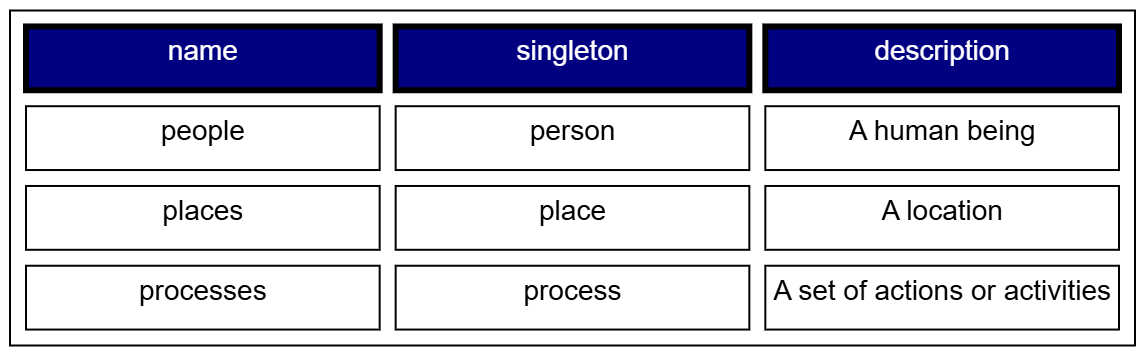
Now, this table is just one form of output. More likely, what you will likely want is an output as XML or JSON (as below), perhaps as an array of JSON objects (a map format). This is what is set by the “format” field in the state object, as given in the listing above:
let output = nsManager.sparql(query, state)
print(output)This will generate the following:
[
{"name":"people","singleton":"person","description":"A human being"},
{”name”:”places”,”singleton”:”place”,”description”:”A location”},
{”name”:”processes”,”singleton”:”process”,”description”:”A set of actions or activities”}
]The specific formats will be somewhat system-dependent, but could include XML, JSON, CSV, YAML, Turtle, HTML & Markdown tables and other formats. It can also be customised. The same kind of templating can be done with class instances and property lists (which I won’t get into here).
Why This Matters
Most people tend to write SPARQL inline, using the language to perform a specific query in much the same way they’d write SQL, and consequently, there tends to be relatively little reuse. However, SPARQL’s ability to perform deep contextual queries and work with data shapes and reification makes the language potentially far more useful; to do so, it also requires taking a more functional viewpoint of the language. Thus, the emphasis on templatisation.
One particular approach here is to name the query template, then generate the query from that. For instance, suppose that you have the template as part of a JavaScript object:
let templates = {"get_classes":`SELECT #@fields *
WHERE {
#@params
?shape a sh:NodeShape.
?shape sh:targetClass ?class .
?shape sh:name ?name .
filter(if(bound(?q) and ?q !=”“,fn:starts-with(lcase(?name),lcase(?q))),true)
optional { ?shape sh:description ?description .}
#@extends
} #@bounds order by ?name limit 100`}, "get_items_from_class":`...`, ...}Then your SPARQL calls become much more straightforward:
let state = {
params:{q:"'p'"},
fields:”?name ?description ?singleton”,
extends:"optional{?shape ex:singleton ?singleton.}",
bounds:"order by ?name limit 20",
format:"map"
}
let results = nsManager.sparql(templates['get_classes'],state)
Or perhaps even:
let state = {
params:{q:"'p'"},
format:"map",
template:"get_classes"
}
nsManager.templates = templates
let results = nsManager.invoke("get_classes",state)This last form is especially important because it is the way that most programmers will want to deal with SPARQL - as a function that can be extended parametrically, without needing to necessarily know the inner workings of what may be very complex queries. It also makes it much easier to abstract the workings of knowledge graphs, because you are always dealing with a shim layer on top of the graph itself.
But what about open linked data, and the idea of having a universal query language on open graphs? I think the evidence speaks for itself. Very few public graphs have actually survived in the twenty-five years since the technology was first introduced. They were over-queried; queries were often greedy, most data has a certain degree of privacy associated with it, too many people needed to know the data models of what they were working with, and on and on.
When you have a database with a billion triples, you do not, in general, want people to have public access to that data except through very controlled channels. As an academic exercise with a comparatively small, self-contained user base, the idea of direct SPARQL access through endpoints makes sense, but once you get into enterprise-level applications, you need to provide a protective layer.
A strategy that provides a queryable interface via an endpoint established with metadata, which can be invoked from an agentic service and that determines the best possible query or mutation based on that metadata, can go a long way towards closing the gap between LLMs and knowledge graphs in terms of usage. This particular post explores (a little) how you can parameterise SPARQL, but the next stage involves providing a mechanism to then inform a service how to call it. This gets into SHACL description documents (SDDs), which I’ll cover soon.
Code for working with the namespace manager in MarkLogic can be retrieved at https://github.com/kurtcagle/namespaceManager . It should be readily adaptable to other environments, and I will continue to maintain it over time.
In media res,

Check out my LinkedIn newsletter, The Cagle Report.
I am also currently seeking new projects or work opportunities. If anyone is looking for a CTO or Director-level AI/Ontologist, please contact me through my Calendly:
If you want to shoot the breeze or have a cup of virtual coffee, I have a Calendly account at https://calendly.com/theCagleReport. I am available for consulting and full-time work as an ontologist, AI/Knowledge Graph guru, and coffee maker. Also, for those of you whom I have promised follow-up material, it’s coming; I’ve been dealing with health issues of late.
I’ve created a Ko-fi account for voluntary contributions, either one-time or ongoing, or you can subscribe directly to The Ontologist. If you find value in my articles, technical pieces, or general thoughts about work in the 21st century, please consider contributing something to support my work, allowing me to continue writing.