
Knowledge Graphs, Context Graphs & Events


The discussion about context graphs, which kicked off a couple of weeks ago in the AI/Semantics community, is now beginning to gain some steam.
I wrote about context graphs earlier [link], but I’ve also had some time to reflect on what context graphs really are, and I’d argue that they are somewhat different from how many people tend to think of knowledge graphs, primarily because they are better at handling events. This is due primarily to the use of reifications.
Capturing Events
In 1991, the Soviet Union, which had existed since 1917, collapsed seemingly overnight. For a while, there was both turmoil and mass protests, and what emerged was (at least for a little while) a Democratic country that mirrored others in Europe - with a president and a Russian Assembly. From a knowledge graph, one country ceased to exist - the USSR - and a new country came into existence - the Russian Federation.
In 1980, the Soviet Union's population was 262 million. By 1990, the population was 289 million. In 2000, the population was 147 million. What’s notable here, of course, is that the Soviet Union no longer existed in 2000, and several oblasts and other regions of what had once been the Soviet Union were now independent (most notably Ukraine).
This represents a common problem with knowledge graphs (and most data modelling strategies). Things change. Populations rise and fall, countries come into existence, grow, shrink, then get absorbed or fade away. Leaders get elected or seize power, then lose elections or are deposed. This holds true for any kind of organisation, and for that matter, most things in the universe. Part of the reason for the complexity of any modelling effort is that while it is comparatively easy to model static things, modelling dynamic, mutable systems is considerably harder.
One way to think about each of these is to understand that these are events that occur on statements. For instance, reading the second paragraph above, you get what seems paradoxical in a “normal” knowledge graph:
Country:SovietUnion Country:hasPopulation 262000000 .
Country:SovietUnion Country:hasPopulation 289000000 .
Country:RussianFederation Country:hasPopulation 147000000 .The reason this seems paradoxical, of course, is that you don’t have enough context. You could create blank node entities that indicate year, which is how, in fact, something like this has been traditionally modelled.
Country:SovietUnion Country:hasPopulation [
Population:value 262000000;
Population:year 1980 ;
] .
Country:SovietUnion Country:hasPopulation [
Population:value 289000000;
Population:year 1990 ;
] .
Country:RussianFederation Country:hasPopulation [
Population:value 147000000;
Population:year 1990 ;
] .
This is a little easier to query, but it’s also still somewhat too simplistic a model. Let’s reframe it: What event occurred that the population changed from 262M people to 289M people? The answer is a Census, which is an Event (a sampling) in which the country's population is counted.
This approach, from a design standpoint, is actually quite useful, because it shifts the discussion away from this property has changed value to: “An event has occurred, and a new value for this property should be read due to that event. Put another way, the graph now explains why a change occurred, rather than just recording that it did.
While not all reifications are events, enough of them are that it’s useful to build a design pattern around an event reification. One way to think about an event is as the association of metadata with a specific triple. For instance, a given census event may look like the following:
Event:1980USSRCensus a Class:Census ;
Census:country Country:SovietUnion ; # same as rdf:subject
Event:property Country:hasPopulation ; # same as rdf:predicate
Census:value 262000000; # same as rdf:object ;
Event:year 1980 ;
.
Class:Census rdfs:subClassOf Class:Event .This is a perfectly valid model, but it has a couple of issues. The first is that for every event, you are essentially repeating three triples that already exist:
Country:SovietUnion Country:hasPopulation 262000000 .
rdf:subject rdf:predicate rdfobject .A reification is a way of reducing this complexity:
Country:SovietUnion Country:hasPopulation 262000000 ~ Event:1980USSRCensus {|
a Class:Census ;
Event:year 1980 ;
|}The tilda “~” identifies the previous triple as the subject, predicate, and object of the reification, while the {| |} expression is analogous to a bracketed blank node. The IRI after the tilda identifies the reification, in this case, the event.
Note that this is different from the triple expression:
<< Country:SovietUnion Country:hasPopulation 262000000 >>A triple expression is, in essence, a statement that can be commented on without actually being a part of the graph. This may be a provisional statement, and the result of this expression is a blank node IRI that can then be used in a triple:
<< Country:SovietUnion Country:hasPopulation 262000000 >> :accordingTo :Jane .Thus, the expression:
Country:SovietUnion Country:hasPopulation 262000000 ~ Event:1980USSRCensus {|
a Class:Census ;
Event:year 1980 ;
|} .Is syntactic sugar for:
Country:SovietUnion Country:hasPopulation 262000000 .
Event:1980USSRCensus rdf:reifies <<( Country:SovietUnion Country:hasPopulation 262000000 )>> .
Event:1980USSRCensus a Class:Census ;
Eventy:year 1980 ;
.It’s worth taking a moment to distinguish between
# blank node reifier
<< Country:SovietUnion Country:hasPopulation 262000000 >> and
# reified expression
<<( Country:SovietUnion Country:hasPopulation 262000000 )>> The blank node reifier << >> assigns a specific blank node identifier to the triple in question. This will differ for each occurrence of the triple and may be something like _:1AC9115DEF1960FA.
Meanwhile, the reified expression <<( )>> signals to the RDF parser that the triple in question should be turned into a reifier with the name specified by rdf:reifies (here Event:1980USSRCensus).
This is one reason the ~ {| |} notation is likely to be more widely utilised - it asserts the triple, performs the reification, and assigns the result to a name with fewer triples.
Changing Identities
As noted, the definition of countries (or most things, to be honest) are typically not static. Countries are formed, they grow, they split, they are absorbed. Historically, we live in a very unusual time when borders and country identities were relatively stable, but it’s not the norm.
The question of when something changes so much that it is no longer considered the same thing is one that arises quite frequently in philosophical circles. With organisations, this is often called the succession problem. When two companies merge, for instance, do they become a new entity or simply continue as the old entity? This has significant implications, both technical and corporate/legal.
The decision to create a new identity is not a technical one; it’s a business or governmental one. Creating that identity, however, is simple:
Country:SovietUnion Country:succeededBy Country:RussianFederation.However, this is a case where you still need metadata to describe the event. What was the event? Succession:
Country:SovietUnion Country:succeededBy Country:RussianFederation
~ Event:TransitionFromUSSRToRF {|
a Class:Succession ;
Event:year 1991 ;
Event:trigger """Dissolution of Soviet Union""" ;
|} .
Class:Succession rdfs:subClassOf Class:Event .The Country:succeededBy predicate is a country property, and is a transitive closure (in most cases where the subject and predicate are the same type, the predicate will likely be a transitive closure. This means that you could get an ordered list of succeeding countries by date, as follows (SPARQL 1.2):
PREFIX Country: <http://example.org/country/>
PREFIX Event: <http://example.org/event/>
PREFIX Class: <http://example.org/class/>
SELECT ?startCountry ?endCountry ?year ?trigger
WHERE {
<< ?startCountry Country:succeededBy ?endCountry >> a Class:Succession ;
Event:year ?year .
OPTIONAL {
<< ?startCountry Country:succeededBy ?endCountry >> Event:trigger ?trigger
}
}
ORDER BY ?yearThis generates the following output: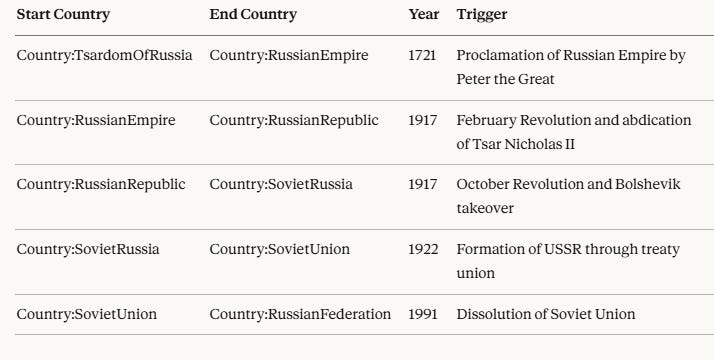
It should be noted that the first entry - the Tsardom of Russia- does not have a year defined. Typically, a succession occurs at the end of a process, while an inception occurs at the beginning. Since this will typically also be the time when the class instance itself is declared, the dataset can be changed as follows:
@prefix Country: <http://example.org/country/> .
@prefix Event: <http://example.org/event/> .
@prefix Class: <http://example.org/class/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
# Class definitions
Class:Inception rdfs:subClassOf Class:Event .
Class:Succession rdfs:subClassOf Class:Event .
# Tsardom of Russia
Country:TsardomOfRussia a Class:Country {|
a Class:Inception ;
Event:year 1547 ;
Event:trigger "Grand Prince Ivan IV proclaimed Tsar of All Russia" ;
|} .
# Tsardom to Russian Empire succession
Country:TsardomOfRussia Country:succeededBy Country:RussianEmpire {|
a Class:Succession ;
Event:year 1721 ;
Event:trigger "Proclamation of Russian Empire by Peter the Great following victory in Great Northern War" ;
|} .
# Russian Empire
Country:RussianEmpire a Class:Country {|
a Class:Inception ;
Event:year 1721 ;
Event:trigger "Peter the Great proclaimed Emperor, transforming Tsardom into Empire" ;
|} .
# Russian Empire to Russian Republic succession
Country:RussianEmpire Country:succeededBy Country:RussianRepublic {|
a Class:Succession ;
Event:year 1917 ;
Event:trigger "February Revolution and abdication of Tsar Nicholas II" ;
|} .
# Russian Republic
Country:RussianRepublic a Class:Country {|
a Class:Inception ;
Event:year 1917 ;
Event:trigger "Establishment of Russian Provisional Government after February Revolution" ;
|} .
# Russian Republic to Soviet Russia succession
Country:RussianRepublic Country:succeededBy Country:SovietRussia {|
a Class:Succession ;
Event:year 1917 ;
Event:trigger "October Revolution and Bolshevik takeover" ;
|} .
# Soviet Russia
Country:SovietRussia a Class:Country {|
a Class:Inception ;
Event:year 1917 ;
Event:trigger "October Revolution established Russian Soviet Federative Socialist Republic" ;
|} .
# Soviet Russia to Soviet Union succession
Country:SovietRussia Country:succeededBy Country:SovietUnion {|
a Class:Succession ;
Event:year 1922 ;
Event:trigger "Formation of USSR through treaty union of Soviet republics" ;
|} .
# Soviet Union
Country:SovietUnion a Class:Country {|
a Class:Inception ;
Event:year 1922 ;
Event:trigger "Treaty on the Creation of the USSR signed by four Soviet republics" ;
|} .
# Soviet Union to Russian Federation succession
Country:SovietUnion Country:succeededBy Country:RussianFederation {|
a Class:Succession ;
Event:year 1991 ;
Event:trigger "Dissolution of Soviet Union following failed August coup" ;
|} .
# Russian Federation
Country:RussianFederation a Class:Country {|
a Class:Inception ;
Event:year 1991 ;
Event:trigger "Declaration of sovereignty and independence following USSR dissolution" ;
|} .This can then be queried with SPARQL (1.2) as follows:
PREFIX Country: <http://example.org/country/>
PREFIX Event: <http://example.org/event/>
PREFIX Class: <http://example.org/class/>
SELECT ?startCountry ?inceptionYear ?inceptionTrigger ?endCountry ?successionYear ?successionTrigger
WHERE {
# Get succession information
<< ?startCountry Country:succeededBy ?endCountry >> a Class:Succession ;
Event:year ?successionYear .
OPTIONAL {
<< ?startCountry Country:succeededBy ?endCountry >> Event:trigger ?successionTrigger
}
# Get inception information for the starting country
OPTIONAL {
<< ?startCountry a Class:Country >> a Class:Inception ;
Event:year ?inceptionYear .
OPTIONAL {
<< ?startCountry a Class:Country >> Event:trigger ?inceptionTrigger
}
}
}
ORDER BY ?inceptionYear ?successionYearThe output is then given as follows:
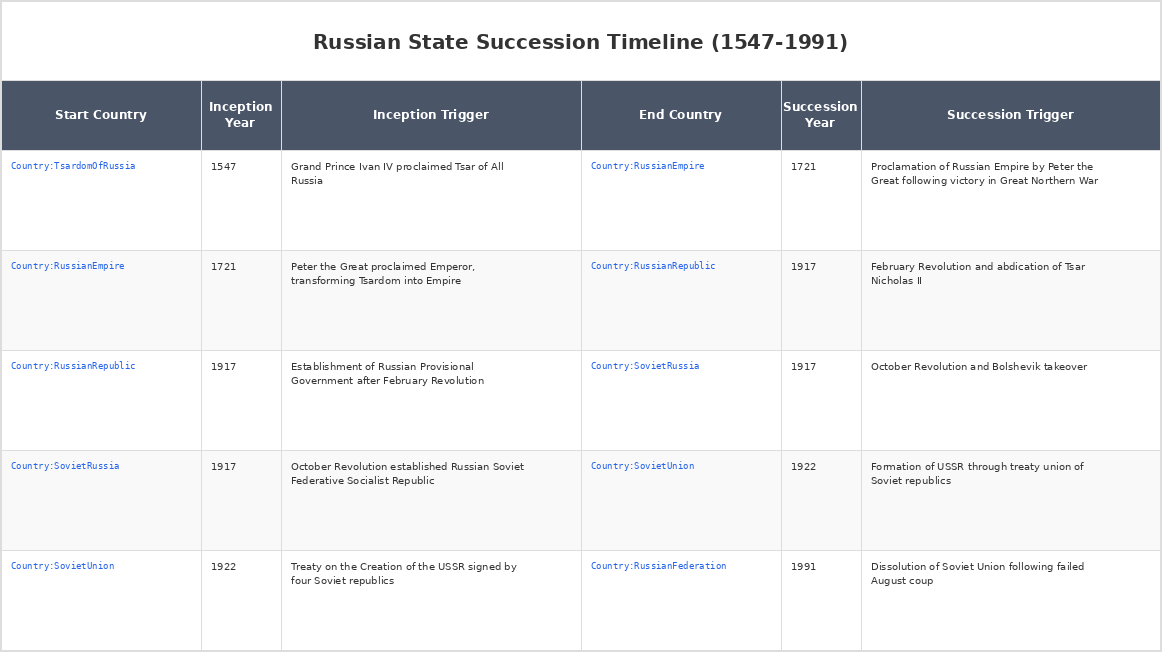
So why would the succession year not be the same as the inception year? When a transition occurs, it may take a while for a new government to form (especially after a war or similar event). In thinking of design, never assume that something starts at the moment that something else ends.
Suppose you have a situation in which a country is absorbed by another. As with inception, a termination event could be associated with the instance declaration. For instance, if Russia were to cease to exist altogether as a political entity in 2105, the entry may very well look like the following:
# Russian Federation
Country:RussianFederation a Class:Country {|
a Class:Termination ;
Event:year 2105 ;
Event:trigger "End of the Russian Federation, no successor states." ;
|} .By the same reasoning, a good system would probably add a termination event for every inception event:
# Soviet Union to Russian Federation succession
Country:SovietUnion a Class:Country {|
a Class:Termination ;
Event:year 1991 ;
Event:trigger "Dissolution of Soviet Union following failed August coup" ;
|} .
SPARQL:
PREFIX Country: <http://example.org/country/>
PREFIX Event: <http://example.org/event/>
PREFIX Class: <http://example.org/class/>
SELECT ?country ?inceptionYear ?inceptionTrigger ?terminationYear ?terminationTrigger ?successorCountry ?successionYear ?successionTrigger
WHERE {
# Get the country
?country a Class:Country .
# Get inception information
OPTIONAL {
<< ?country a Class:Country >> a Class:Inception ;
Event:year ?inceptionYear .
OPTIONAL {
<< ?country a Class:Country >> Event:trigger ?inceptionTrigger
}
}
# Get termination information
OPTIONAL {
<< ?country a Class:Country >> a Class:Termination ;
Event:year ?terminationYear .
OPTIONAL {
<< ?country a Class:Country >> Event:trigger ?terminationTrigger
}
}
# Get succession information
OPTIONAL {
<< ?country Country:succeededBy ?successorCountry >> a Class:Succession ;
Event:year ?successionYear .
OPTIONAL {
<< ?country Country:succeededBy ?successorCountry >> Event:trigger ?successionTrigger
}
}
}
ORDER BY ?inceptionYear ?countryArchetypes
When dealing with transient organisations, it’s often useful to see these as being part of a broader “archetype”. For instance, all of these countries could technically be considered “Russia” even though they had different governing structures and hierarchies. By creating a Country:archetype property on a country, you can use that archetype to talk about the historical evolution of the archetype over time.
# Soviet Union
Country:SovietUnion a Class:Country ~ Event:USSRFounded {|
a Class:Inception ;
Event:year 1922 ;
Event:trigger "Treaty on the Creation of the USSR signed by four Soviet republics" ;
|};
Class:archetype Country:Russia ;
.
# Russian Federation
Country:RussianFederation a Class:Country ~ Event:RFFounded {|
a Class:Inception ;
Event:year 1991 ;
Event:trigger "Declaration of sovereignty and independence following USSR dissolution" ;
|} ;
Class:archetype Country:Russia ;
.
Country:Russia a Class:Country ;
rdfs:comment "An abstract archetype of the country of Russia ";
.This archetype approach is also useful for dealing with media characters, such as the character Catwoman in the DC universe. This character has existed for 85 years and has had more than two dozen distinctive incarnations across various media, many of them overlapping. As with countries and companies, versioning can become quite complex because the world itself is rarely linear in its evolution.
Context Graphs and Reification Pointers
What emerges when you start working with reified events is a shift away from the notion that you capture whole “records” and instead view properties as ways to sample specific properties as events. The base knowledge graph does not store records so much as potential states that a given property can be in, with reification events then identifying which of those states are of interest in any particular context.
Another way of thinking about this is that there are two interconnected graphs at work. The first represents things atemporally - the list of countries, the list of characters, the list of books, and their connections to one another. This graph, the knowledge graph, is timeless in that it says nothing about when, where, why, or how; it only asserts that these things exist, have existed, or may exist at some point in the future.
The second graph is the reification or context graph. This graph lives in the reifications. It says that the Soviet Union was a thing in 1945, but that it is not a thing, save as a historical reference, in 2026. The knowledge graph indicates succession, for instance, but does not provide the context for that succession - the context graph does that.
In grammatical terms, a reification can be thought of as a prepositional phrase. Restating the Turtle from above,
# Soviet Union
Country:SovietUnion a Class:Country
~ Event:USSRFounded {|
a Class:Inception ;
Event:year 1922 ;
Event:trigger "Treaty on the Creation of the USSR signed by four Soviet republics" ;
|};
Class:archetype Country:Russia ;
~ Event:USSREnded {|
a Class:Termination ;
Event:year 1991 ;
Event:trigger "Dissolution of the Soviet Union following a failed August coup" ;
|} ;
Country:succeededBy Country:RussianFederation ~ Event:USSR2RF {|
a Class:Succession ;
Event:year 1991 ;
|} ;
.
# Russian Federation
Country:RussianFederation a Class:Country {|
a Class:Inception ;
Event:year 1991 ;
Event:trigger "Declaration of sovereignty and independence following USSR dissolution" ;
|} ;
Class:archetype Country:Russia ;
.This tells a story, a narrative:
The Soviet Union, a Country, was founded in 1922, with the "Treaty on the Creation of the USSR signed by four Soviet republics". It was ended in 1991 with the "Dissolution of the Soviet Union following a failed August coup." It was succeeded by the Russian Federation in 1991, with the "Declaration of sovereignty and independence following USSR dissolution". Note that without the reifications, the story still holds, but loses its temporality or context:
# Soviet Union
Country:SovietUnion a Class:Country
Class:archetype Country:Russia ;
Country:succeededBy Country:RussianFederation ;
.
# Russian Federation
Country:RussianFederation a Class:Country ;
Class:archetype Country:Russia ;
.Which can be read as:
The Soviet Union, a Country, is an archetype of Russia and was succeeded by the Russian Federation, also an archetype of Russia.The knowledge graph can, of course, be expanded to include other things, explicitly calling out events as subordinate data:
Country:SovietUnion a Class:Country
Class:archetype Country:Russia ;
Country:succeededBy Country:RussianFederation ;
Country:hasCensus Event:1980USSRCensus, Event:1990USSRCensus;
.
Event:1980USSRCensus a Class:Census ;
Census:population 262000000;
Event:year 1980 ;
.
Event:1990USSRCensus a Class:Census ;
Census:population 289000000;
Event:year 1990 ;
.
This can also be recast in reification terms:
Country:SovietUnion a Class:Country
Class:archetype Country:Russia ;
Country:succeededBy Country:RussianFederation ;
Country:hasCensus
[Census:population 262000000] {| Event:year 1980 |} ,
[Census:population 289000000] {| Event:year 1990 |} ;
.Note the use of the bracketed blank node expressions. The Turtle above for the 1980 Census alone is:
Country:SovietUnion Country:hasCensus
[Census:population 262000000] {| Event:year 1980 |} .which can be decomposed as:
Country:SovietUnion Country:hasCensus _:b1 .
_:b1 Census:population 262000000 ;
<< Country:SovietUnion Country:hasCensus _:b1 >> Event:year 1980 .This can be taken one step further with named reifications:
Country:SovietUnion a Class:Country
Class:archetype Country:Russia ;
Country:succeededBy Country:RussianFederation ;
Country:hasCensus
[Census:population 262000000] ~ Census:USSR1980 {| Event:year 1980 |} ,
[Census:population 289000000] ~ Census:USSR1990 {| Event:year 1990 |} ;
.Put another way, this makes it possible to name a bracketed blank node expression, something that has been missing from Turtle. It should be noted that you’re not really naming the blank node (giving it a reference). Rather, you are giving a name to the reification whose object is this blank node. You can then retrieve the blank node itself in SPARQL as follows:
SELECT ?population WHERE {
VALUES ?reifier { Census:USSR1980 }
BIND(OBJECT(?reifier) as ?census)
?census Census:population ?population
} This pattern holds true any time that you have subordinate objects that are temporal in nature, such as addresses:
Person:Jane Doe a Class:Person ;
Person:hasAddress [
Address:city City:Boston ;
Address:state State:MA ;
] ~ Event:JaneBostonAddress {| Event:from 1995; Event:to 2010 |},
[
Address:city City:Seattle ;
Address:state State:WA ;
] ~ Event:JaneSeattleAddress {| Event:from 2010; |} ;
.Finally, you can add one other critical element:
Person:Jane Doe a Class:Person ;
Person:hasAddress [
Address:city City:Boston ;
Address:state State:MA ;
Address:succeededBy Event:JaneSeattleAddress ; # Succession Info!
] ~ Event:JaneBostonAddress {| Event:from 1995; Event:to 2010 |} ,
[
Address:city City:Seattle ;
Address:state State:WA ;
] ~ Event:JaneSeattleAddress {| Event:from 2010; |} ;
.Here, the Address:succeedBy property indicates the next address where Jane lived (a forwarding address, if you will). You still need to dereference that reifier with the OBJECT() property in SPARQL, mind you:
SELECT ?nextCity ?nextState WHERE {
VALUES ?firstAddressPointer {Event:JaneBostonAddress}
BIND( OBJECT(?firstAddressPointer) as ?firstAddress )
?firstAddress Address:succeededBy ?nextAddressPointer .
BIND( OBJECT(?nextAddressPointer) as ?nextAddress )
?nextAddress Address:city ?nextCity .
?nextAddress Address:state ?nexstState .
}You can even bypass the bind and do this directly as statements:
SELECT ?nextCity ?nextState WHERE {
VALUES ?firstAddressPointer {Event:JaneBostonAddress}
OBJECT(?firstAddressPointer) Address:succeededBy ?nextAddressPointer .
OBJECT(?nextAddressPointer) Address:city ?nextCity ;
Address:state ?nexstState .
}There are many advantages to this approach. First, by being able to specify succeeding addresses (or similar resources), you don’t have to perform (very slow) boundary checks or date-based ordering. One of the most common complaints about SPARQL is that it is slow, but this is because SPARQL queries are slow, often due to issues like reordering or bounding. Link traversal, on the other hand, is blazingly fast in comparison.
Additionally, this creates a linked list in time. While not all linked lists are temporal, most are. Even those that aren’t (such as chapters in a book), still follow a narrative order, which is fundamentally temporal - you generally read chapter 2 before you read chapter 3.
Spatial Movement
A similar pattern can handle World Graphs. A world graph is, like a context graph, a graph built around spatial movement. For instance, consider a chess game. For each piece, you can identify a sequence of moves. The following depicts the movement of the white king’s knight (WKN), on a grid with the rows numbered 1 to 8 (from White's perspective) and the columns numbered A-H.
ChessPiece:WKN a Class:ChessPiece ;
rdfs:label "White King's Knight" ;
ChessPiece:startsAt Position:g1 ;
ChessPiece:hasPosition
Position:f3 ~ _:WKN-g1-f3 {| Event:at 1; Event:game ChessGame:101 |} ,
Position:e5 ~ _:WKN-f3-e5 {| Event:at 3; Event:game ChessGame:101 |} ,
Position:f7 ~ _:WKN-E5-F7 {| Event:at 5; Event:game ChessGame:101; ChessGame:takes ChessPiece:BPF |} ,
Position:H8 ~ _:WKN-F7-D8 {| Event:at 7; Event:game ChessGame:101; ChessGame:takes ChessPiece:BKR |} ;
.Here, BPf is Black Pawn starting in column f, BKR is Black King’s Rook.
Note that in the annotations, there are two critical pieces of information - which turn is being specified, and which game this applies to. Put another way, there is only one White King’s Knight in the system, but it’s being used in every chess game.
This can also be modelled differently:
ChessGame:101 a Class:ChessGame ;
rdfs:label "Chess Game 101 ;
ChessGame:hasWhitePlayer Player:1249;
ChessGame:hasBlackPlayer Player:718;
ChessGame:hasMove
[
Move:chessPiece ChessPiece:WKN ;
Move:startAt Position:g1 ;
Move:endAt Position:f3 ;
Move:playerSide PlayerSide:White ;
Move:nextMove _:BPd-d7-d6 ;
] ~ _:WKN-g1-f3 {| Event:turn 1 |} ,
[
Move:chessPiece ChessPiece:BPd ;
Move:startAt Position:g1 ;
Move:endAt Position:f3 ;
Move:playerSide PlayerSide:Black ;
Move:nextMove _:WKN-e5-d7 ;
] ~ _:BPd-d7-d6 {| Event:turn 2 |},
[
Move:chessPiece ChessPiece:WKN ;
Move:startAt Position:f3 ;
Move:endAt Position:e5 ;
Move:playerSide PlayerSide:White ;
Move:nextMove _:BPe-e7-e6 ;
] ~ _:WKN-e5-d7 {| Event:turn 3 |} ,
... ;
.In this case, the game identifies the players (and associates them with a given side), then has a collection of moves, with each step identified by a (named) blank node and having an event tag indicating the turn. Note in this case that Event:turn is likely useful but not necessary, since the game still has a linked list entry pointing to the next move. This means the annotations could be dropped, leaving just the annotation name.
ChessGame:101 a Class:ChessGame ;
rdfs:label "Chess Game 101 ;
ChessGame:hasWhitePlayer Player:1249;
ChessGame:hasBlackPlayer Player:718;
ChessGame:hasMove
[
Move:chessPiece ChessPiece:WKN ;
Move:startAt Position:g1 ;
Move:endAt Position:f3 ;
Move:playerSide PlayerSide:White ;
Move:nextMove _:Turn-101-2 ;
Move:turn 1;
] ~ _:Turn101-1 ,
[
Move:chessPiece ChessPiece:BPd ;
Move:startAt Position:g1 ;
Move:endAt Position:f3 ;
Move:playerSide PlayerSide:Black ;
Move:nextMove _:Turn-101-3 ;
Move:turn 2;
] ~ _:Turn101-2 ,
[
Move:chessPiece ChessPiece:WKN ;
Move:startAt Position:f3 ;
Move:endAt Position:e5 ;
Move:playerSide PlayerSide:White ;
Move:nextMove _:Turn-101-4 ;
Move:turn 3;
] ~ _:Turn101-3 ,
... ;A few takeaways here: I’m using named blank nodes rather than IRIs for the move pointers because these moves are relative to the game, rather than to the whole of the graph. These will be automatically converted to blank node IRIs by the system's parser. I’ve also added a Move:turn property and changed the named reifier names to ones that are likely to be more unique.
The movements could be given in terms of absolute positioning, but in many circumstances, you may be better off working with a grid or similar partitioning, in which each permissible location on the board has a specific IRI address and identifier. This becomes especially important when dealing with multi-user environments.
Next()
This all may seem fairly prosaic, so why is this a discussion about context graphs? The answer is surprisingly simple: Reifications let you associate events - temporal context - with assertions. This means that you shift how you think about knowledge graphs, not as a way of storing data but as a way of describing the valid potential states of a state machine. It means you can create linked sequences across time, making it easier to identify a traversal pathway for a resource located within a graph representation of a spatial map.
Think of this state machine as being constructable but immutable. What I mean is that you can add new information to the state machine, but you can’t delete information that has already been added. This is by design; most problems with bad information architecture stem from the fact that most databases are mutable, meaning they cannot preserve provenance or context without extensive ad hoc design.
Once you get into reifications, you are moving back into the realm of pointers and dereferencing. These are essential for hypergraphs, but they are also essential for time-aware context graphs.
Reification, however, is not quite enough. You need the ability to say “when a certain contextual pattern emerges, add specific new triples into the graph”. These are rules. OWL has this capability, but it tends to be limited to inferencing across specific configuration sets and properties. To build a dynamic state machine, you need to be able to control rules within the graph itself.
This is where SHACL Rules come in. A SHACL rule identifies nodes that satisfy a given context, then creates new triples in an output graph based upon that contextual information. It marries validation, contextualisation and content output, and it is essential for context graphs.
One key point - there’s a lot of talk about context graphs, but the reality is that there are very few even PoC implementations, especially among the transformer-only crowd. This is because you need to understand not only state machines but also how graphs themselves work, and personally, the semantic web community has been chewing on this problem for nearly a decade now.
I will be continuing this thread in an upcoming post.
In Media Res,

Check out my LinkedIn newsletter, The Cagle Report.
I am also currently seeking new projects or work opportunities. If anyone is looking for a CTO or Director-level AI/Ontologist, please get in touch with me through my Calendly:
If you want to shoot the breeze or have a cup of virtual coffee, I have a Calendly account at https://calendly.com/theCagleReport. I am available for consulting and full-time work as an ontologist, AI/Knowledge Graph guru, and coffee maker. Also, for those of you whom I have promised follow-up material, it’s coming; I’ve been dealing with health issues of late.
I’ve created a Ko-fi account for voluntary contributions, either one-time or ongoing, or you can subscribe directly to The Ontologist. If you value my articles, technical pieces, or general reflections on work in the 21st century, please consider contributing to support my work and allow me to continue writing.
Fantastic breakdown of reifications in context graphs. The linked list approach for temporal ordering instead of date-based boundary checks is clever, I've seen similar performance issues with slow SPARQL queries that could benefit from this. The chess game example makes the spatial movement concept click instantly. One thing I'm curious about is how you handle conflicts when differnet sources report different event years for the same succession.
What is your take on W3C Prov with respect to it's ability to model Context Graphs (in the context - sorry - of this essay)?
In other words, can W3C Prov (specifically PROV-O) meet the requirements of a Context Graph as you define it?