
Inferential vs. Structural Ontologies


One thing I’ve been emphasising of late is the importance of SHACL 1.2 from a structural standpoint rather than an inference standpoint (as in OWL). These aren’t the same, though they overlap somewhat, and they indicate why SHACL may be better suited to application development, particularly for the generative use of LLM code generators.
This is a long piece. because I think that the distinction between structural and inferential ontologies is important. One is not better than the other, and at the edges, SHACL in particular is quite capable of inferencing, and more to the point, building other inferential ontologies.
Inferential Ontologies
RDF early on developed a reputation for its use in inference, primarily because one of the first formal ontologies developed within the framework was OWL (the Web Ontology Language), along with a somewhat older specification called SKOS (the Simple Knowledge Organisation System). SKOS at its core mirrored the Linnaean taxonomy system developed by Swedish Biologist Carl Linnaeus in the 18th century, which focused on organising classes in terms of specificity (skos:narrower and skos:broader).
OWL, on the other hand, had its antecedents in the symbolic logical systems used in mathematics, which in turn dates back to the Principia Mathematica, written by Bertrand Russell and Alfred North Whitehead from 1910 to 1913. This work was significant both because it helped formalise much of the mathematical notation of the time, and because it was, in its own way, a precursor to much of the computing theory that would dominate over the next century. A sample of its contents, though, illustrates the fact that it was a fairly dense slog to understand, especially as much of it was built around set theory and propositional calculus:

Much of what went into the Principia Mathematica became known as First-Order or Formal Logic. RDF was seen as a way of encoding assertions (the p’s, q’s, and r’s in the above list), and OWL, in turn, was seen as specifying (some of) the logical class relationships of such assertions. OWL is consequently fairly rigorous mathematically, but much of its use ultimately depended on applying such calculus (that which calculates) to draw inferences.
An inference can be thought of as a logical proof that looks for specific patterns within logic as a way of constructing new terminology (typically, but not exclusively, classes). For instance, you can identify a sibling relationship:
RULE: a PERSON A has a SIBLING B
IF: A has a PARENT C, AND
B has a PARENT C.
Building such inferential systems is one key method for reasoning about the system, and is critical for deductive reasoning in particular (if you know that two people are siblings, for instance, you can infer that they have at least one common parent). You can also compose relationships via such inference:
RULE: a person A has a COUSIN B
IF: A has a PARENT C, AND
B has a PARENT D, AND
C != D, AND
C has an AN ANCESTOR E, AND
D has an AN ANCESTOR EThis requires that you have a definition of ANCESTOR, which can be stated as:
RULE: a person A has an ANCESTOR B
IF: A has a PARENT C
C either IS or HAS an ANCESTOR BThis is a recursive rule in which a particular relationship is derived by recursion until a given condition is met. This kind of recursive relationship, in the general sense, is called a transitive closure, for what it’s worth. Most inheritance of properties are defined in a class-oriented system, ultimately, in the same way.
Inferential reasoning is powerful, but it primarily focuses on classes and properties used to derive logical statements.
Both OWL and SKOS are ontologies, not because they are inferential systems, but because they each use a specific set of classes and relationships (properties) tailored to their particular requirements. SKOS classes describe concepts, their specificity relative to other concepts, and their annotations, which is very useful when discussing taxonomies. OWL classes describe classes and properties that describe formal logical systems used for reasoning. A construction ontology describes the classes and properties that indicate how a building is assembled.
Tom Gruber (who went on to co-found SIRI) put this into a pithy definition in 1993:
An ontology is a specification of a conceptualization."
Put another way, an ontology is the set of rules and primitives needed to describe a relational system. Some ontologies are designed for inferential reasoning, some are used for categorisation, and some are intended for specifying how buildings (or pizzas) are put together. And some are used to describe structure.
Inferential vs Structural Ontologies
A structural ontology differs from an inferential ontology in a few critical ways (this is assuming SHACL 1.2):
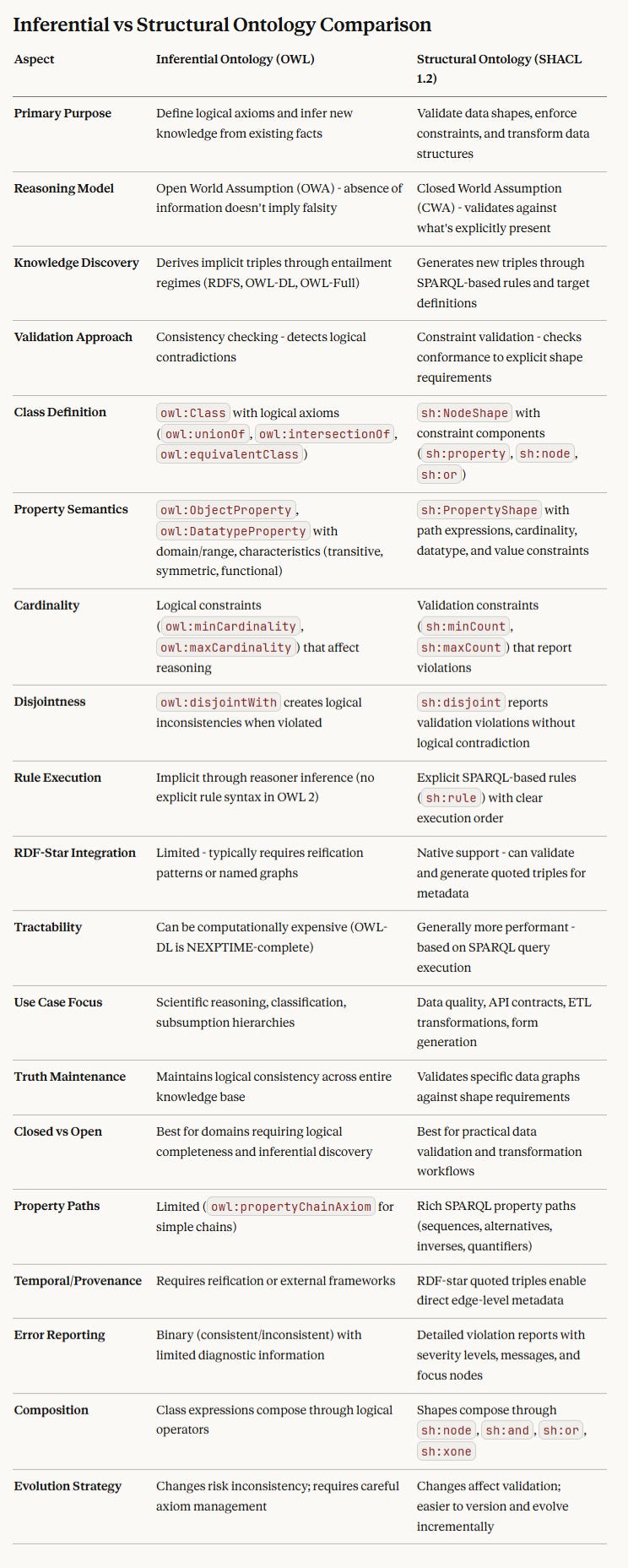
(A small clarification on the above - the default for SHACL is an open world assumption, however, SHACL supports both).
The Shape Constraint Language (SHACL) is based on a different set of underlying design decisions than OWL. Its intent is not to facilitate inferential reasoning, but only to describe structure. That is to say, SHACL associates contextual definitions for classes and properties based upon the presence of specific predicates:
VERSION "1.2" # Signifies RDF 1.2, primarily for reification
@prefix sh: <http://www.w3.org/ns/shacl#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix ex: <http://example.org/> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
# ============================================
# Person Shape with Family Relationships
# ============================================
ex:PersonShape
a sh:NodeShape ;
sh:targetClass ex:Person ;
sh:property ex:ParentProperty,
ex:ChildProperty,
ex:SiblingProperty,
ex:AncestorProperty,
ex:CousinProperty ;
sh:rule ex:InferChildFromParent,
ex:InferSiblingFromSharedParent,
ex:InferAncestorTransitive,
ex:InferCousinFromParentSiblings ;
.
# ============================================
# Direct Property Constraints
# ============================================
ex:ParentProperty
a sh:PropertyShape ;
sh:path ex:parent ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "parent" ;
sh:description "Direct biological or adoptive parent relationship" ;
sh:message "Parent must be another Person" ;
.
ex:ChildProperty
a sh:PropertyShape ;
sh:path ex:child ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "child" ;
sh:description "Direct biological or adoptive child relationship" ;
sh:message "Child must be another Person" ;
.
ex:SiblingProperty
a sh:PropertyShape ;
sh:path ex:sibling ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "sibling" ;
sh:description "Person who shares at least one parent" ;
sh:message "Sibling must be another Person" ;
# Siblings are symmetric
sh:sparql [
sh:message "Sibling relationship must be symmetric" ;
sh:prefixes ex: ;
sh:select """
SELECT $this ?sibling
WHERE {
$this ex:sibling ?sibling .
FILTER NOT EXISTS { ?sibling ex:sibling $this }
}
""" ;
] ;
# A person cannot be their own sibling
sh:sparql [
sh:message "A person cannot be their own sibling" ;
sh:prefixes ex: ;
sh:select """
SELECT $this
WHERE {
$this ex:sibling $this .
}
""" ;
] ;
.
ex:AncestorProperty
a sh:PropertyShape ;
sh:path ex:ancestor ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "ancestor" ;
sh:description "Transitive relationship through parent lineage" ;
sh:message "Ancestor must be another Person" ;
.
ex:CousinProperty
a sh:PropertyShape ;
sh:path ex:cousin ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "cousin" ;
sh:description "Person who shares at least one grandparent but no parents" ;
sh:message "Cousin must be another Person" ;
# Cousins are symmetric
sh:sparql [
sh:message "Cousin relationship must be symmetric" ;
sh:prefixes ex: ;
sh:select """
SELECT $this ?cousin
WHERE {
$this ex:cousin ?cousin .
FILTER NOT EXISTS { ?cousin ex:cousin $this }
}
""" ;
] ;
# Cousins cannot be siblings
sh:sparql [
sh:message "Cousins cannot also be siblings" ;
sh:prefixes ex: ;
sh:select """
SELECT $this ?cousin
WHERE {
$this ex:cousin ?cousin .
$this ex:sibling ?cousin .
}
""" ;
] ;
.
# ============================================
# Inference Rules
# ============================================
# Rule: If A is parent of B, then B is child of A
ex:InferChildFromParent
a sh:SPARQLRule ;
sh:prefixes ex: ;
sh:construct """
CONSTRUCT {
?child ex:child ?parent .
}
WHERE {
?parent ex:parent ?child .
FILTER NOT EXISTS { ?child ex:child ?parent }
}
""" ;
.
# Rule: If A and B share a parent, they are siblings
ex:InferSiblingFromSharedParent
a sh:SPARQLRule ;
sh:prefixes ex: ;
sh:construct """
CONSTRUCT {
?person1 ex:sibling ?person2 .
?person2 ex:sibling ?person1 .
}
WHERE {
?parent ex:parent ?person1 .
?parent ex:parent ?person2 .
FILTER (?person1 != ?person2)
FILTER NOT EXISTS { ?person1 ex:sibling ?person2 }
}
""" ;
.
# Rule: Infer transitive ancestor relationships
ex:InferAncestorTransitive
a sh:SPARQLRule ;
sh:prefixes ex: ;
sh:construct """
CONSTRUCT {
?descendant ex:ancestor ?ancestor .
}
WHERE {
{
# Direct parent is an ancestor
?ancestor ex:parent ?descendant .
FILTER NOT EXISTS { ?descendant ex:ancestor ?ancestor }
}
UNION
{
# Parent's ancestors are also ancestors (transitive)
?ancestor ex:parent ?intermediate .
?descendant ex:ancestor ?intermediate .
FILTER NOT EXISTS { ?descendant ex:ancestor ?ancestor }
}
}
""" ;
.
# Rule: If parents are siblings, children are cousins
ex:InferCousinFromParentSiblings
a sh:SPARQLRule ;
sh:prefixes ex: ;
sh:construct """
CONSTRUCT {
?person1 ex:cousin ?person2 .
?person2 ex:cousin ?person1 .
}
WHERE {
?parent1 ex:parent ?person1 .
?parent2 ex:parent ?person2 .
?parent1 ex:sibling ?parent2 .
FILTER (?person1 != ?person2)
# Ensure they don't share a parent (i.e., aren't siblings)
FILTER NOT EXISTS {
?sharedParent ex:parent ?person1 .
?sharedParent ex:parent ?person2 .
}
FILTER NOT EXISTS { ?person1 ex:cousin ?person2 }
}
""" ;
.
# ============================================
# Additional Constraint: Prevent Cyclic Parentage
# ============================================
ex:PersonShape
sh:sparql [
sh:message "A person cannot be their own ancestor (cyclic parentage detected)" ;
sh:prefixes ex: ;
sh:select """
SELECT $this
WHERE {
$this ex:ancestor $this .
}
""" ;
] ;
.
# ============================================
# Example Data for Testing
# ============================================
ex:Alice a ex:Person ;
ex:parent ex:Carol ;
ex:parent ex:David ;
.
ex:Bob a ex:Person ;
ex:parent ex:Carol ;
ex:parent ex:David ;
.
ex:Charlie a ex:Person ;
ex:parent ex:Eve ;
ex:parent ex:Frank ;
.
ex:Carol a ex:Person ;
ex:parent ex:Grace ;
.
ex:Eve a ex:Person ;
ex:parent ex:Grace ;
.
ex:Grace a ex:Person .
ex:David a ex:Person .
ex:Frank a ex:Person .
# Expected inferences:
# - Alice and Bob are siblings (share Carol and David)
# - Carol is child of Grace, Eve is child of Grace
# - Carol and Eve are siblings
# - Alice, Bob, and Charlie are cousins (their parents Carol and Eve are siblings)
# - Grace is ancestor of Alice, Bob, Charlie, Carol, and EveThe Person class is described by a node shape (ex:PersonShape) associated with a target class (ex:Person) has several sh:property elements that indicate direct properties, in general, with the properties associated with a given predicate. For instance, the ex:ParentProperty shape is bound via sh:path to the predicate ex:parent.
ex:ParentProperty
a sh:PropertyShape ;
sh:path ex:parent ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "parent" ;
sh:description "Direct biological or adoptive parent relationship" ;
sh:message "Parent must be another Person" ;
.These direct properties are non-inferential - they tell you what kinds of nodes are attached to one another via properties, but they make no assumption about the semantics intrinsic to those nodes.
In addition to these direct properties, there are additional constraints, such as a constraint to make sure that a given person cannot be a parent to themselves:
ex:PersonShape
sh:sparql [
sh:message "A person cannot be their own ancestor (cyclic parentage detected)" ;
sh:prefixes ex: ;
sh:select """
SELECT $this
WHERE {
$this ex:ancestor $this .
}
""" ;
] ;
.If this sh:select If a SPARQL query returns a value for $this, it is deemed a validation error (a person cannot be their own ancestor, time travel notwithstanding).
Note that this is not a logical inference, per se - it tells you about the relationships of certain types of nodes within the graph, rather than the relationships of the concepts that those nodes represent. This is a subtle but important distinction: SHACL makes no direct conceptual assumptions; it is only concerned with the structure of the graph.
Why is this important? OWL, as an inferential ontology, assumes that all triples in the graph are valid within the model's validity parameters. If some triples are invalid, then the conclusions (inferences) being drawn may be invalid as well, and consequently, when inconsistencies arise in your inferences, then you have to check your intervening assumptions. This is consistent with how mathematical theorems are constructed, by the way, and are at the core of any large-scale logical system.
SHACL, on the other hand, makes no assumptions about the validity of a given assertion. It is only important that the assumption (the set of triples) in question follow the constraints imposed by the schema. This means that SHACL will not, by itself, determine logical validity; it will determine only structural integrity.
You can have logically invalid data in a SHACL-based knowledge graph. Sometimes, that invalidity is due to uncertainty (the date of birth of a particular person may be ambiguous, or the reporter of that information may be unreliable). Sometimes (especially with reification), you may have statements that are true some of the time, but false at other times. Sometimes you are positing the existence of something that doesn’t in fact exist, in order to see what happens (which is about the cleanest definition of a simulation I can think of).
The point is that simply because an assertion (a triple or set of triples) is in a graph does not render it as being valid or “true”. It only means that the assertion(s) are in the graph. This is the operating assumption under which SHACL operates.
This assumption is used by most data modelling languages, including UML, XSD, and even JSON Schema. It is, in fact, a weaker assumption than OWL, but it also means that SHACL can model structure in a manner more familiar to most programmers than OWL does.
Does this mean that SHACL is superior to OWL? No. Modelling the structure of a graph is important, so is logical inferences. They, however, do different things. If you need to describe the rules of whether a graph is structurally valid, you use SHACL. If you need to determine whether the concepts represented by the graph's nodes are logically consistent, you use OWL.
That said, you can use SHACL to create inferential ontologies, including OWL.
SHACL Rules and Inferential Systems
A SHACL Rule combines a validation step on an existing graph with a construction step to create new triples in a target graph. In general, the assumption is that the target graph is specified externally by the rules engine itself, though discussions about a sh:targetGraph property have been raised in the working group.
This is originally how OWL and early triple stores worked, with one major difference. In OWL, the rules were static and typically defined in external profiles. In theory, one could change those rule-sets; in practice, these systems were slow enough that most people stuck with a single “official” profile (or were even unaware that such profiles existed). This gave rise to “magical inferencing”, where the rules of logic were unpredictable from system to system.
SHACL switches the conversation to some extent because you can build custom inference rules. To a certain extent, this is what SPARQL does with CONSTRUCT statements (and what SPARQL UPDATE does, albeit in an immutable fashion for triples that are round-tripped back into named graphs).
The immutability is an important distinction between the two, especially with respect to recursion.
When the SHACL Graph is invoked, it actually doesn’t read just from the source graph. Rather, it reads from the Total Graph, which combines the Source Graph and the Inference Graph (where the triples are sent upon completion).
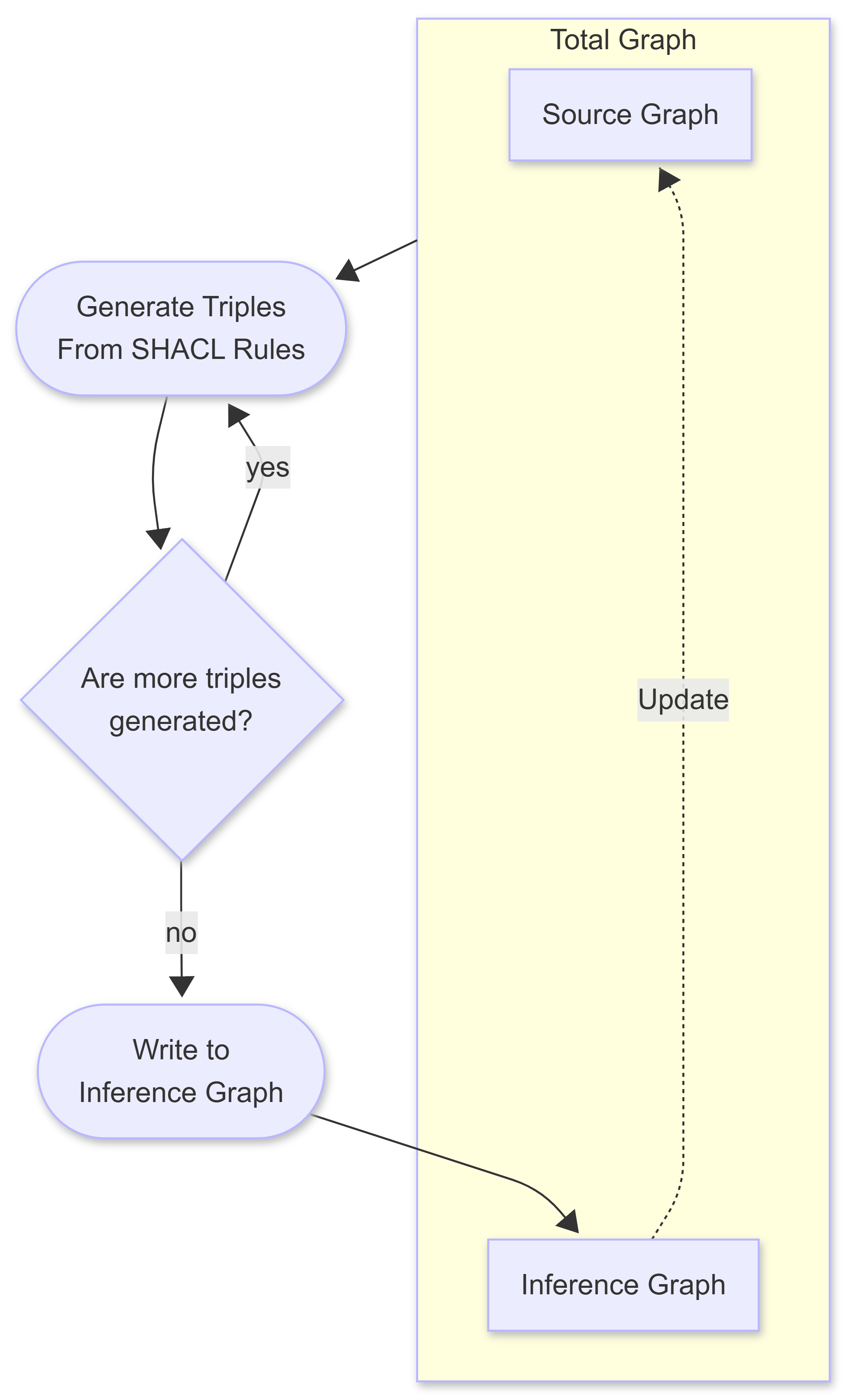
The SHACL transformer repeats this process until no new triples are generated, which is a form of recursion. One implication is that triples created in one iteration of this process can, in turn, be used in the total graph in the next iteration. Triples that have already been used in the inference graph are not reinvoked in this process. Another implication (which was true of OWL as well) is that you can create an infinite loop this way if you’re not fairly careful about how you write your rules, so it’s likely that any rules engine evaluator should be able to raise a stack overflow error and reset the graph before committing it.
It’s also likely that an operation can be invoked on the inference graph to perform a commit and reset, which adds the contents of the inference graph to the source graph and then clears the inference graph. Note that this architecture remains under discussion, but it reflects the SHACL working group's current thinking as of the end of January 2026.
Note that this behaviour differs from that of SPARQL UPDATE, which performs a single pass update over matching nodes in the system (once) and returns the results directly to the graph without an intervening “sanity check” stage. I favour the SHACL approach because it enables effective rollback of changes and yields declarative, immutable, and non-destructive results.
This recursiveness makes transitive relationships feasible. For instance, in the previous section, one rule enabled the identification of ancestors.
# Rule: Infer transitive ancestor relationships
ex:InferAncestorTransitive
a sh:SPARQLRule ;
sh:prefixes ex: ;
sh:construct """
CONSTRUCT {
?descendant ex:ancestor ?ancestor .
}
WHERE {
{
# Direct parent is an ancestor
?ancestor ex:parent ?descendant .
FILTER NOT EXISTS { ?descendant ex:ancestor ?ancestor }
}
UNION
{
# Parent's ancestors are also ancestors (transitive)
?ancestor ex:parent ?intermediate .
?descendant ex:ancestor ?intermediate .
FILTER NOT EXISTS { ?descendant ex:ancestor ?ancestor }
}
}
""" ;
.Unlike SPARQL, which uses ex:parent property paths, the SHACL approach generates triples. For instance, when this rule is run, ex:Alice ends up with two ex:ancestor relationships:
ex:Alice ex:ancestor ex:Carol, ex:Grace .This is the core of what inference means: following a set of rules to identify new relationships between objects and then naming those relationships. It doesn’t necessarily discover new facts; it only makes existing relationships more obvious and, consequently, indexable.
Note that the ex:ancestor The predicate is still defined within SHACL in terms of attributes, distinct from its rule definition.
ex:AncestorProperty
a sh:PropertyShape ;
sh:path ex:ancestor ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "ancestor" ;
sh:description "Transitive relationship through parent lineage" ;
sh:message "Ancestor must be another Person" ;
.This definition is significant because it indicates that, even when properties are inferred, the property predicate must still be part of the model.
Inferential relationships can explicitly cover other core OWL functions. For instance, if ex:Jane is married to ex:John, it follows that ex:John is also married to ex:Jane.
# ============================================
# Marriage Property and Inference
# ============================================
ex:MarriedToProperty
a sh:PropertyShape ;
sh:path ex:marriedTo ;
sh:nodeKind sh:IRI ;
sh:class ex:Person ;
sh:name "married to" ;
sh:description "Person to whom this person is married" ;
sh:message "Spouse must be another Person" ;
# Marriage is symmetric
sh:sparql [
sh:message "Marriage relationship must be symmetric" ;
sh:prefixes ex: ;
sh:select """
SELECT $this ?spouse
WHERE {
$this ex:marriedTo ?spouse .
FILTER NOT EXISTS { ?spouse ex:marriedTo $this }
}
""" ;
] ;
# A person cannot be married to themselves
sh:sparql [
sh:message "A person cannot be married to themselves" ;
sh:prefixes ex: ;
sh:select """
SELECT $this
WHERE {
$this ex:marriedTo $this .
}
""" ;
] ;
.
# Rule: If A is married to B, then B is married to A
ex:InferMarriageSymmetry
a sh:SPARQLRule ;
sh:prefixes ex: ;
sh:construct """
CONSTRUCT {
?person2 ex:marriedTo ?person1 .
}
WHERE {
?person1 ex:marriedTo ?person2 .
FILTER NOT EXISTS { ?person2 ex:marriedTo ?person1 }
}
""" ;
.You would also need to add both rule and property to the ex:Person shape:
ex:PersonShape
a sh:NodeShape ;
sh:targetClass ex:Person ;
sh:property ex:ParentProperty,
ex:ChildProperty,
ex:SiblingProperty,
ex:AncestorProperty,
ex:CousinProperty,
ex:MarriedToProperty ; # Add this
sh:rule ex:InferChildFromParent,
ex:InferSiblingFromSharedParent,
ex:InferAncestorTransitive,
ex:InferCousinFromParentSiblings,
ex:InferMarriageSymmetry ; # Add this
.The SPARQL property shape sets the relevant shape attributes and includes two sh:sparql properties: one tests whether the relationship is symmetric (if A is married to B, then B is married to A), and the other ensures that no one is married to themselves. The inference, on the other hand, builds new ex:marriedTo properties that ensure that the relationship is symmetrical.
OWL would accomplish this with a specific declaration that a property (here ex:marriedTo) was a subclass of the class owl:SymmetricProperty :
ex:marriedTo
a owl:ObjectProperty, owl:SymmetricProperty, owl:IrreflexiveProperty ;
rdfs:domain ex:Person ;
rdfs:range ex:Person ;
rdfs:label "married to" ;
rdfs:comment "Symmetric relationship indicating marriage between two persons" .
In this case, you would have to know that a symmetric property identifies an “IF A p B then B p A” relationship, while an irreflexive property indicates that the same relationship is not true when A = B (you can’t be married to yourself).
As should be evident, you can build these OWL relationships and classes using SHACL rules and properties. The question is why you would want to do so. There are a couple of good answers: the first is that it allows you to perform more rigorous validation on your datasets, using custom SHACL messages that can be tied to specific property definitions at a level that OWL does not offer.
A second answer is that with SHACL building OWL constructs, you can merge a shape-based structural language with an inference-based reasoning language, giving you the best of both worlds. You do not need to have a specific dependency upon an OWL processor or a limited (and often difficult to access) set of profiles, but can instead create a package that embodies the whole of an ontology, structural and inferential, from first principles.
The final answer, however, is subtler and, in some respects, more important.
Structure, Inferencing and AI
I do not believe the problem with LLMs is that they inherently lie. Lying, by its very nature, implies intent, and while I believe that the corpus of training material may (indeed, certainly does) contain errors, biased information, unsubstantiated content, and deliberate falsehoods, these are not something that is intrinsic to the mechanism of the LLM (though guardrails set up after the fact may very well be a different story).
Instead, hallucinations are mathematical artefacts that occur either because there is a gap in the latent space or because the information is too dense with alternatives, such that even a low sensitivity threshold could tip into an alternative-narrative threshold. In effect, the model is either too undertrained or too overtrained. This is also why there is a limit to AI scaling.
If you assume (as I have in previous posts) that a latent space forms a quasi-graph (it’s a fuzzy graph, if you will), then inferencing on an LLM is actually analogous to creating an amorphous chain of “reasoning”, which can be thought of as a sheaf or bundle of interconnected paths in this narrative structure. Because narratives are directed (they have a distinct direction due to word ordering in language), an encoding of these concept clouds roughly also follow a distinct ordering due to the way that we stucture sentences - conditional expressions, noun clauses, verb clauses and so forth, predicate clauses and so forth, which in turn create distinct biases in how narrative structures are then formed within an LLM.
However, there is no “graph” in a formal sense; rather, there are clusters of related or subsequent terms with a directional bias. This creates contiguous strings of word clouds, with terms such as “cat” and “feline” occurring in close proximity because they often denote the same conceptual entity. There may be millions of potential narrative paths, but once you add the shaped, directed graph of a prompt, the number of narratives quickly decreases.
If I provide an ontology (schema + taxonomy) to such an LLM, it uses the literals within the ontology to provide hooks into the cloud, then utilises the graph connections within the ontology to preferentially connect them. This works because these sequences of triples are stronger connections than what exists within the LLM, and consequently create a preferred ordering. If I pass the ontology and a preferred data sample into the LLM, the data sample again predominates over the LLM and consequently adheres to the ontology preferentially.
There are several consequences of this. Current data mapping techniques between formats, or from unstructured to structured data, are generally ineffective because the cost and complexity of these transformations can be prohibitive, especially when the data is highly unstructured or has a largely ad hoc, one-off structure (e.g., spreadsheets).
If unstructured or semi-structured data can “coalesce” around the shape specified by an ontology, the accuracy is likely to be quite high, and the per-document cost is likely to be substantially lower (even accounting for tokenisation costs). Additionally, because SHACL provides schematic constraint validation, converted content can also be tested to ensure that it is both well-formed and satisfies not only syntactic but also contextual (i.e., semantic) constraints.
Note that this does not guarantee that a document will map WELL to a given ontology if the document is not semantically relevant, but even here, the inability to map to required fields could very well provide an indicator that you’re trying to map a cat to a car. Additionally, transcription and hallucination errors can still occur, but the loss of fidelity due to hallucinations with a proper schema has historically been far lower (< 0.1%) compared to that of unconstrained conversions (>10%).
I have another article in the works, specifically discussing additional epistemological data and why you should never assume that any data you work with is completely accurate and truthful.
Why is SHACL preferable to OWL for representing these ontologies in an AI context? Empirically, it has a higher conversion success rate, but the reasons are likely not obvious.
Most older ontologies implicitly assume that they are decomposable into distinct files, with many assuming that the OWL ontology is already implicit within a reasoner. This is not always incorporated properly into an LLM. Because OWL primarily defines relationships for inferencing within the reasoner, more complex ontologies don’t always incorporate all components.
Similarly, many knowledge graph engines store these files in a catalogue for lookup; because the catalogue is an application-level construct, those links are lost.
Structural languages such as SHACL are lower-level constructs built around shapes, constraints, and rules. In this sense, they are more consistent, whereas OWL often has multiple different ways of expressing the same set of constraints. I like to say that SHACL is closer to machine language in that regard: it requires more to describe a structure, but it is highly regular, especially when expressed in Turtle (which may be processed more easily than JSON-LD, though I have only anecdotal evidence for that).
SHACL tends to be better documented (because it has both standardised and custom error messages when validation fails), and because you can add additional metadata to SHACL at both the property and class levels, this tends to make LLMs better at inferring intent from data.
SHACL node expressions and rules include mechanisms for computing values that would otherwise be computed directly in SPARQL.
Claude, Deepseek, and OpenAI are all SHACL aware, though they may not necessarily be hooked into the absolute latest proposed version (1.2). (I normally specify that Claude should use the 1.2 definition specified at https://www.w3.org/TR/shacl12-core/ ).
I often split my ontologies into schema and taxonomy files, with the taxonomy defined in SKOS and the taxonomy enumeration broken down into broad rather than deep trees.
@prefix Person: <http://example.com/ns/Person#> .
@prefix Class: <http://example.com/ns/Class#> .
@prefix Profession: <http://example.com/ns/Profession#> .
@prefix Concept: <http://example.com/ns/Concept#> .
@prefix Teacher: <http://example.com/ns/Teacher#> .
@prefix School: <http://example.com/ns/School#> .
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix sh: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
# Profession Taxonomy
Concept:Teacher a skos:Concept, a Concept:Educator ;
skos:prefLabel "Teacher" ;
skos:broader Concept:Educator ;
.
Concept:Educator a skos:Concept, a Concept:Profession ;
skos:prefLabel "Educator" ;
skos:broader Concept:Profession ;
.
# Subject Taxonomy
Concept:Subject a skos:Concept, a Concept:Topic ;
skos:prefLabel "Subject" ;
skos:broader Concept:Topic ;
.
Concept:Mathematics a skos:Concept, Concept:Subject ;
skos:prefLabel "Mathematics" ;
skos:broader Concept:Subject ;
.
Concept:Science a skos:Concept, Concept:Subject ;
skos:prefLabel "Science" ;
skos:broader Concept:Subject ;
.
Concept:English a skos:Concept, Concept:Subject ;
skos:prefLabel "English" ;
skos:broader Concept:Subject ;
.
# School Instance
School:JamesonElementarySchool a Class:School ;
skos:prefLabel "Jameson Elementary School" ;
.
# Person Instance
Person:JaneDoe a Class:Person ;
skos:prefLabel "Jane Doe" ;
Person:hasProfession Concept:Teacher ;
Teacher:taughtAt School:JamesonElementarySchool ;
Teacher:taughtSubject Concept:Mathematics ;
.
# SHACL Structure - constrain that profession must be Teacher
_:TeacherShape
a sh:NodeShape ;
sh:targetClass Class:Person ;
sh:property [
sh:path Person:hasProfession ;
sh:class skos:Concept ;
sh:hasValue Concept:Teacher ;
sh:minCount 1 ;
], [
sh:path Teacher:taughtAt ;
sh:class Class:School ;
sh:minCount 1 ;
], [
sh:path Teacher:taughtSubject ;
sh:class Concept:Subject ;
sh:minCount 1 ;
] .
If a person has a profession of a teacher (they have Person:hasProfession Concept:Teacher), they automatically have the property Teacher:taughtAt , with one or more schools, and Teacher:taughtSubject, with one or more school subjects. The difference here is that Schools is a potentially growing list of many potentially complex objects (which may be more differentiated than concepts), whereas Subjects is likely a small, managed list within a taxonomy.
This isn’t quite the best way to model this, by the way; you’d probably be better off modelling a Teaching Job object as an event. This example is just intended to show how you could create classes without having to do complex formal subclassing, while still retaining a taxonomy.
Whether the taxonomy is a formal part of the ontology or part of the dataset is largely immaterial from the standpoint of AI, although some triple stores use separate graphs for SHACL to improve performance. As a general rule, if a particular enumerated list is small (fewer than 1000 items) and relatively stable, placing the taxonomy under SHACL makes sense. If the list is > 1000 items or is unstable (changes rapidly), it’s better to identify these strictly as classes.
Note that you can also test SHACL rules in Claude or Deepseek (I haven’t tried it in ChatGPT, but it should work there as well). I’ll be covering this in an upcoming post.
Conclusion
Ontological schemas are a design approach that constrains a solution, regardless of whether it is used with a triple store or an LLM. SHACL can be thought of as a semantic machine language that establishes expectations and generates new rules from existing data, even when that data is unstructured text (transcripts, emails, contracts, press releases, CVs, legal structures, raw tables, and similar materials) processed by LLMs. Inferences can be accomplished with SHACL by itself or with SHACL rules, and SHACL rules can, in turn, define the behaviour of higher-order inferential ontologies such as OWL.
In Media Res,

Check out my LinkedIn newsletter, The Cagle Report.
I am also currently seeking new projects or work opportunities. If anyone is looking for a CTO or Director-level AI/Ontologist, please get in touch with me through my Calendly:
If you want to shoot the breeze or have a cup of virtual coffee, I have a Calendly account at https://calendly.com/theCagleReport. I am available for consulting and full-time work as an ontologist, AI/Knowledge Graph guru, and coffee maker. Also, for those of you whom I have promised follow-up material, it’s coming; I’ve been dealing with health issues of late.
I’ve created a Ko-fi account for voluntary contributions, either one-time or ongoing, or you can subscribe directly to The Ontologist. If you value my articles, technical pieces, or general reflections on work in the 21st century, please consider contributing to support my work and allow me to continue writing.
You seem to mention four (4) purposes (kinds?) of tautologies, yet only compare two of them: “…
Some ontologies are designed for inferential reasoning, some are used for categorisation, and some are intended for specifying how buildings (or pizzas) are put together. And some are used to describe structure. …”, followed by a table only comparing two (2) of the 4 kinds.
Confusing version number typo in the very first line (I thought I'd somehow missed a massive leap!): "One thing I’ve been emphasising of late is the importance of SHACL 2.1..." :)