
Deconstructing Sentences: Context Graphs and Reification
Making your graphs more natural-language oriented

Looking back, my first real encounters with graphs I remember date back to English class in junior high school. The teacher worked with us for about a week on documenting sentences. Most of the kids thought it was really pointless, but it stuck with me for some reason, and gave me my first inkling that language and graphs were intimately related.
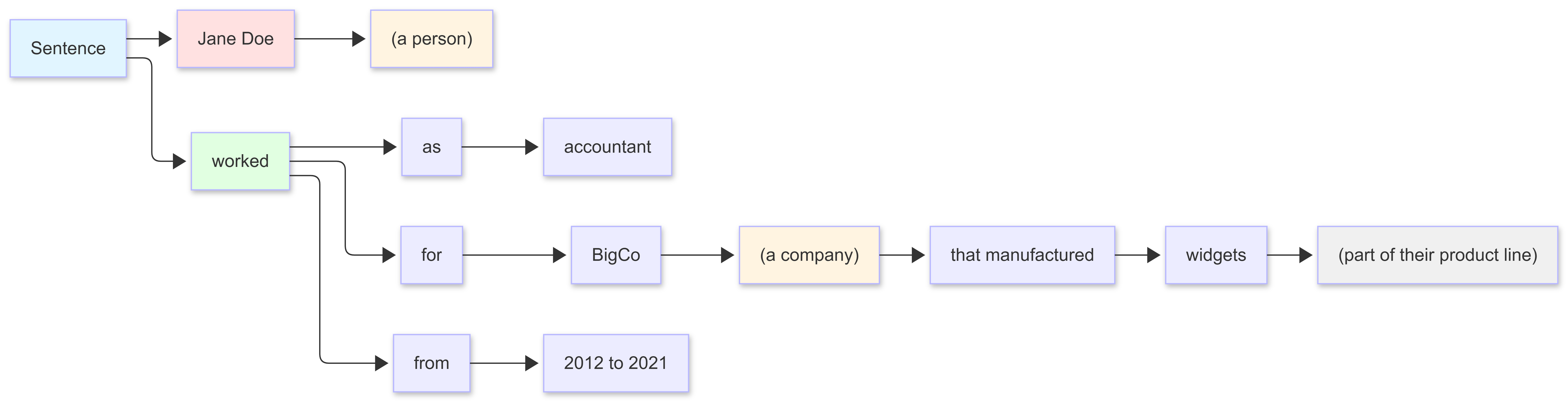
Consider the following sentence:
Jane Doe, a person, worked as an accountant for BigCo, a company that manufactured widgets (part of their product line) from 2012 to 2021. The graph for this is directed, starting with an implicit root node (Sentence):
This, by the way, is exactly how an LLM sees a sentence. It is not, however, how you would encode this information in a knowledge graph. The normal approach to encapsulating this in RDF looks something like this:
ex:JaneDoe a ex:Person ;
ex:WorkedAs ex:Accountant ;
ex:WorkedFor ex:BigCo ;
ex:from "2012 ;
ex:top "2021" .
ex:BigCo a ex:Company ;
ex:manufactured ex:Widget;
ex:hasProductLine ex:BigCoProductLine .
ex:Widget a ex:Product ;
ex:partOf ex:BigCoProductLine .Put another way, most semantic modelling takes a class/property/instance approach. This requires identifying both classes and properties in advance, and it is far from intuitive, especially when you add inheritance (and other forms of inference) into the mix.
Ironically, while this captures a lot of information, in some respects it loses information as well that’s more subtle. Some of this is basic modelling that doesn’t become obvious until you have more of the story:
Jane Doe, a person, worked as an accountant for BigCo, a company that manufactured widgets (part of their product line) from 2012 to 2021. After that, in 2021, she became a senior accountant at BigCo until 2023, when Jane went on to work for SmallCo, a startup, as their CFO. SmallCo produced Whizbangs, which were similar to Widgets, but more advanced. This can be represented (almost verbatim) as reified Turtle:
PREFIX ex: <http://example.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
ex:JaneDoe a ex:Person ; rdfs:label "Jane Doe" .
ex:BigCo a ex:Company .
ex:SmallCo a ex:Startup .
ex:Widget a ex:Product .
ex:Whizbang a ex:Product .
ex:JaneDoe ex:workedFor ex:BigCo
{| ex:role "Accountant" ; ex:start "2012"^^xsd:gYear ; ex:end "2021"^^xsd:gYear |} ,
{| ex:role "Senior Accountant" ; ex:start "2021"^^xsd:gYear ; ex:end "2023"^^xsd:gYear |} ;
ex:workedFor ex:SmallCo
{| ex:role "CFO" ; ex:start "2023"^^xsd:gYear |} .
ex:BigCo ex:produces ex:Widget {| ex:inProductLine true |} .
ex:SmallCo ex:produces ex:Whizbang .
ex:Whizbang ex:similarTo ex:Widget {| ex:moreAdvanced true |} .In essence, there are now three distinct properties of Jane Doe working for someone: two for BigCo and one for SmallCo (a startup). This is shown in the following diagram:
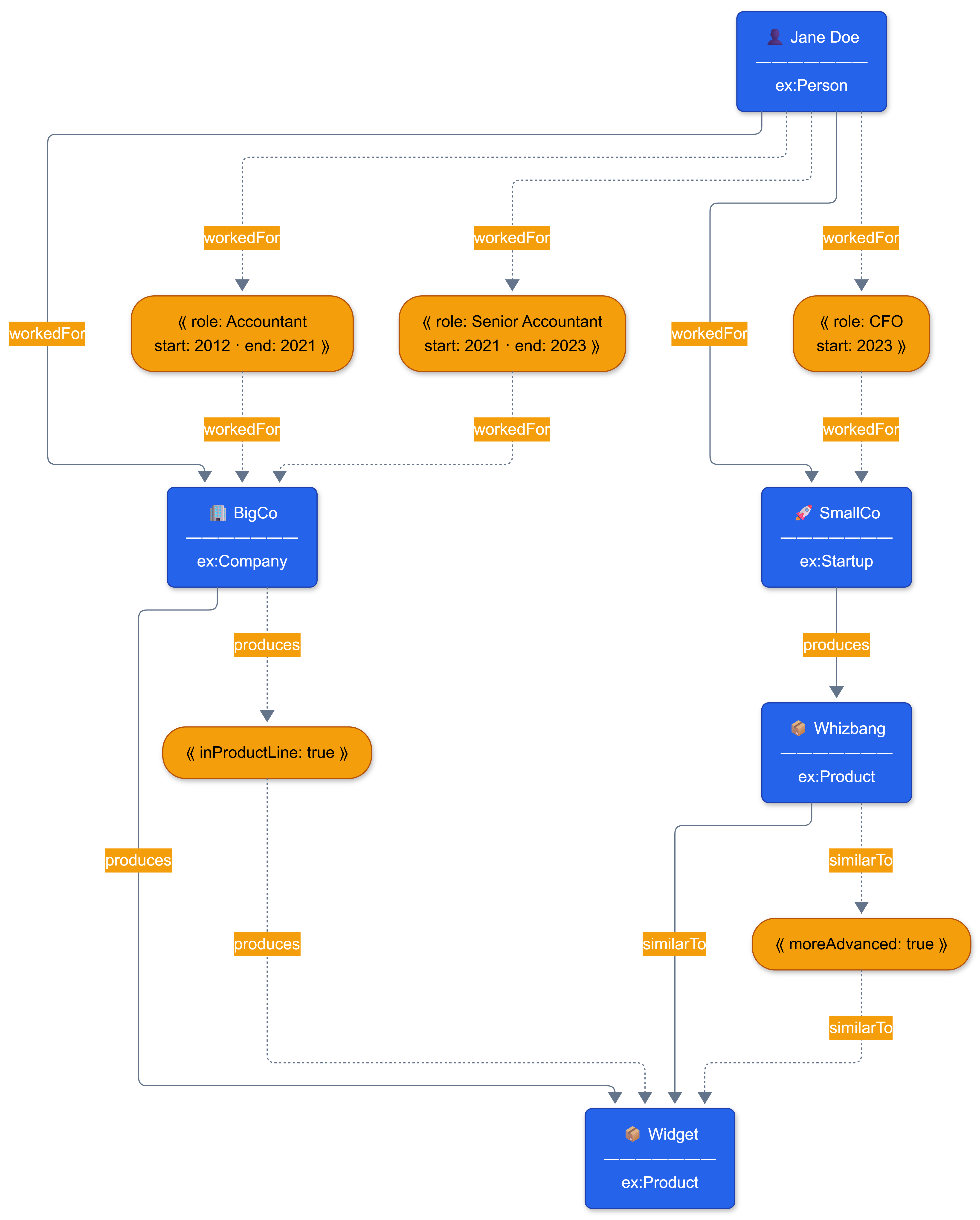
Another way to think about this is that RDF-Star reifiers create connections between triples, rather than just between nodes. The blue items represent the declared nodes. The labeled edges also contain connections that represent the triple as a subject, not just the predicate itself.
One of the big differences to note here is that the annotation itself likely has a distinct class, depending on the triple. For instance, in the relationship
?person ex:workedFor ?companythe expectation is that the annotation (or reification) class will be something like ex:Employment.
What do I mean by reification class? When you create an assertion, the predicate of that assertion (such as ex:workedFor) implies that there exists an object that can describe that relationship in depth. The class of that object is the reification class. For instance, ex:workedFor implies an employment or job class (let’s choose the former as it is more closely associated with long-term work). The reification can then be rewritten as:
ex:JaneDoe ex:workedFor ex:BigCo ~ {|
a ex:Employment ;
ex:role "Accountant";
ex:start "2012"^^xsd:gYear ;
ex:end "2021"^^xsd:gYear
|} .In this case, ex:Employment can be seen as the reification class, with the additional properties being the properties defined by that class.
All reifications have a reification class.
This is true of any kind of blank node structure, by the way - the attributes of a data structures can collectively be identified as a class. For reifications, that class is usually the noun variant of the predication relationships (ex:workedFor → ex:Employment).
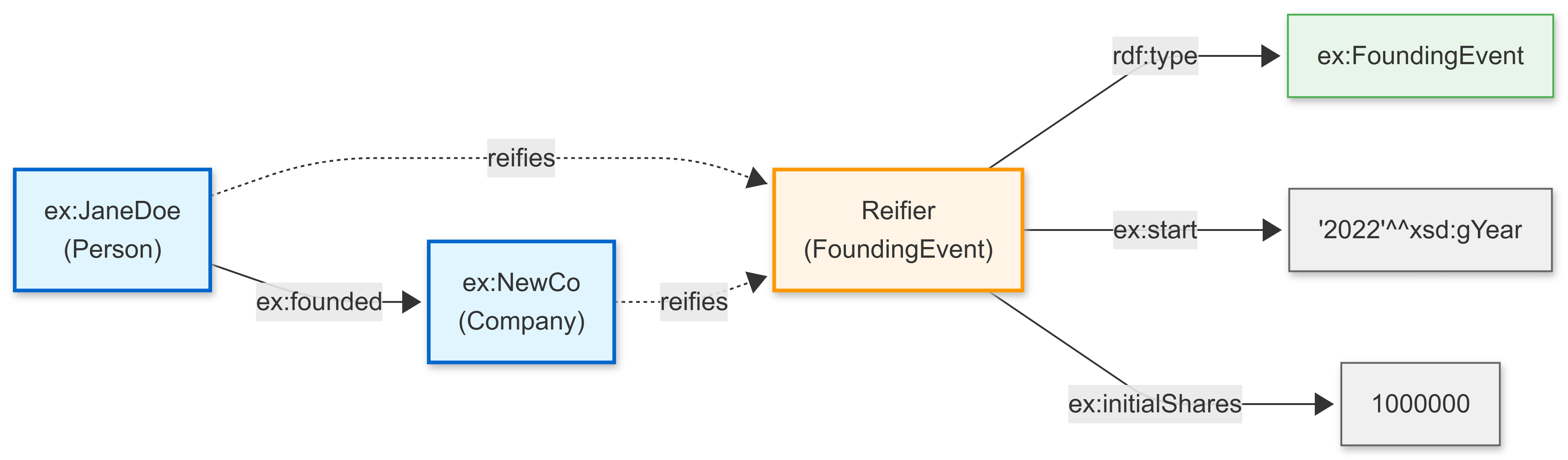
Note that the same subject and object classes may have multiple reification classes dependent upon the predicate. For instance,
ex:JaneDoe ex:founded ex:NewCo ~ {|
a ex:FoundingEvent ;
ex:start “2022”^^xsd:gYear ;
ex:initialShares 1000000 ;
|} .has the same subject and object classes (ex:Person and ex:Company respectively) but the predicate creates a different type of reification class.
Significantly, the reifier class here is also a subclass of event. This creates another lemma:
Most reifier classes will be some form of an event, typically describing an activity.
This isn’t always true (especially when subject and object are of the same class) but any time you have an indication of a process (worked at, founded) there’s usually going to be an event involved as the reifier class.
SHACL 1.2 can make such reifier classes explicit, through reifier shapes:
@prefix ex: <http://example.org/> .
@prefix sh: <http://www.w3.org/ns/shacl#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
# Shape for the founder (subject)
ex:FounderShape
a sh:NodeShape ;
sh:targetClass ex:Person ;
sh:property [
sh:path ex:founded ;
sh:nodeKind sh:IRI ;
sh:class ex:Company ;
sh:minCount 0 ;
sh:reifierShape ex:FoundingEventReifierShape ;
] .
# Shape for validating the reifier (annotations)
ex:FoundingEventReifierShape
a sh:NodeShape ;
sh:class ex:FoundingEvent ;
sh:property [
sh:path ex:start ;
sh:datatype xsd:gYear ;
sh:minCount 1 ;
sh:maxCount 1 ;
],
sh:property [
sh:path ex:initialShares ;
sh:nodeKind sh:Literal ;
sh:minCount 1 ;
sh:datatype xsd:integer;
sh:minValueInclusive 0 ;
] .In this case, the sh:reifierShape property identifies a node shape that, in turn, defines what a founding event should look like.
Again, getting back to the sentence graphing, the above modelled Turtle translates direction into a natural language description:
Jane Doe founded NewCo in 2022, receiving 1,000,000 initial shares.
This can be viewed graphically as follows:
The whole Turtle content can then be stated as:
PREFIX ex: <http://example.org/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
ex:JaneDoe a ex:Person ; rdfs:label "Jane Doe" .
ex:BigCo a ex:Company .
ex:SmallCo a ex:Startup .
ex:NewCo a ex:Startup .
ex:Widget a ex:Product .
ex:Whizbang a ex:Product .
ex:JaneDoe ex:workedFor ex:BigCo
{| ex:Employment ;
ex:role "Accountant" ;
ex:start "2012"^^xsd:gYear ;
ex:end "2021"^^xsd:gYear |} ,
{| ex:Employment ;
ex:role "Senior Accountant" ;
ex:start "2021"^^xsd:gYear ;
ex:end "2022"^^xsd:gYear |} ;
ex:workedFor ex:SmallCo
{| ex:Employment ;
ex:role "CFO" ;
ex:start "2023"^^xsd:gYear ;
ex:end "2025 |} ;
ex:founded ex:NewCo ~ {|
a ex:FoundingEvent ;
ex:start “2026”^^xsd:gYear ;
ex:initialShares 1000000 ;
|} .
ex:BigCo ex:produces ex:Widget {| ex:inProductLine true |} .
ex:SmallCo ex:produces ex:Whizbang .
ex:Whizbang ex:similarTo ex:Widget {| ex:moreAdvanced true |} .By the way, this can also be represented in a similar “near verbatim” style as Open Cypher:
// Create Person nodes
CREATE (janeDoe:Person {
uri: 'http://example.org/JaneDoe',
label: 'Jane Doe'
})
// Create Company nodes
CREATE (bigCo:Company {
uri: 'http://example.org/BigCo'
})
CREATE (smallCo:Startup {
uri: 'http://example.org/SmallCo'
})
CREATE (newCo:Startup {
uri: 'http://example.org/NewCo'
})
// Create Product nodes
CREATE (widget:Product {
uri: 'http://example.org/Widget'
})
CREATE (whizbang:Product {
uri: 'http://example.org/Whizbang'
})
// Employment relationships (with reified properties)
CREATE (janeDoe)-[:WORKED_FOR {
type: 'Employment',
role: 'Accountant',
start: 2012,
end: 2021
}]->(bigCo)
CREATE (janeDoe)-[:WORKED_FOR {
type: 'Employment',
role: 'Senior Accountant',
start: 2021,
end: 2023
}]->(bigCo)
CREATE (janeDoe)-[:WORKED_FOR {
type: 'Employment',
role: 'CFO',
start: 2023,
end: 2025
}]->(smallCo)
// Founding relationship (with reified properties)
CREATE (janeDoe)-[:FOUNDED {
type: 'FoundingEvent',
start: 2026,
initialShares: 1000000
}]->(newCo)
// Production relationships
CREATE (bigCo)-[:PRODUCES {
inProductLine: true
}]->(widget)
CREATE (smallCo)-[:PRODUCES]->(whizbang)
// Product comparison relationship
CREATE (whizbang)-[:SIMILAR_TO {
moreAdvanced: true
}]->(widget) The similarity here between the two should be obvious; if your are modeling with reifications, the mapping between Turtle 1.2 and Open Cypher becomes considerably cleaner than if you are using the older OWL modelling approach.
Finally, the reified forms can make for cleaner JSON-LD as well:
{
"@context": {
"ex": "http://example.org/",
"rdfs": "http://www.w3.org/2000/01/rdf-schema#",
"xsd": "http://www.w3.org/2001/XMLSchema#",
"label": "rdfs:label",
"workedFor": "ex:workedFor",
"founded": "ex:founded",
"produces": "ex:produces",
"similarTo": "ex:similarTo",
"role": "ex:role",
"start": {
"@id": "ex:start",
"@type": "xsd:gYear"
},
"end": {
"@id": "ex:end",
"@type": "xsd:gYear"
},
"initialShares": {
"@id": "ex:initialShares",
"@type": "xsd:integer"
},
"inProductLine": {
"@id": "ex:inProductLine",
"@type": "xsd:boolean"
},
"moreAdvanced": {
"@id": "ex:moreAdvanced",
"@type": "xsd:boolean"
}
},
"@graph": [
{
"@id": "ex:JaneDoe",
"@type": "ex:Person",
"label": "Jane Doe",
"workedFor": [
{
"@id": "ex:BigCo",
"@annotation": {
"@type": "ex:Employment",
"role": "Accountant",
"start": "2012",
"end": "2021"
}
},
{
"@id": "ex:BigCo",
"@annotation": {
"@type": "ex:Employment",
"role": "Senior Accountant",
"start": "2021",
"end": "2023"
}
},
{
"@id": "ex:SmallCo",
"@annotation": {
"@type": "ex:Employment",
"role": "CFO",
"start": "2023",
"start": "2025"
}
}
],
"founded": {
"@id": "ex:NewCo",
"@annotation": {
"@type": "ex:FoundingEvent",
"start": "2026",
"initialShares": 1000000
}
}
},
{
"@id": "ex:BigCo",
"@type": "ex:Company",
"produces": {
"@id": "ex:Widget",
"@annotation": {
"inProductLine": true
}
}
},
{
"@id": "ex:SmallCo",
"@type": "ex:Startup",
"produces": "ex:Whizbang"
},
{
"@id": "ex:NewCo",
"@type": "ex:Startup"
},
{
"@id": "ex:Widget",
"@type": "ex:Product"
},
{
"@id": "ex:Whizbang",
"@type": "ex:Product",
"similarTo": {
"@id": "ex:Widget",
"@annotation": {
"moreAdvanced": true
}
}
}
]
}Here the “@annotation” directive provides the reification content.
Conclusion
There are several takeaways here:
Reifications can make the translation from natural language expressions into Turtle 1.2 (and vice versa) much more natural, as well as making for more compact code.
The use of reifications also makes going between Turtle and Open Cypher (Neo4J’s LPG language much easier, as does translation to and from JSON-LD and YAML-LD.
Reifications have annotation classes, frequently based upon activity or process. That is to say, when you create a reifier, you aren’t just creating random properties - there’s usually something being described.
Context graphs and knowledge graphs frequently overlap - there’s usually no magical divide that separates one from the other, but as a general rule, the more that you build on events as the foundation of things (and hence need to annotate activity) the more context-graph-like your hypergraph becomes.
Once you see narrative as a series of consecutive events, and see reification as a mechanism to qualify subordinate clauses in narrative structures, modelling tends to become more natural, and more closely aligned with how we build world models.
In Media Res,

If you like these articles, please consider becoming a paid subscriber. It helps support me so that I can continue writing code, in-depth analyses, educational pieces, and more.
Check out my LinkedIn newsletter, The Cagle Report.
I am also currently seeking new projects or work opportunities. If anyone is looking for a CTO or Director-level AI/Ontologist, please get in touch with me through my Calendly:
If you want to shoot the breeze or have a cup of virtual coffee, I have a Calendly account at https://calendly.com/theCagleReport. I am available for consulting and full-time work as an ontologist, AI/Knowledge Graph guru, and coffee maker. Also, for those of you whom I have promised follow-up material, it’s coming; I’ve been dealing with health issues of late.
I’ve created a Ko-fi account for voluntary contributions, either one-time or ongoing, or you can subscribe directly to The Ontologist. If you value my articles, technical pieces, or general reflections on work in the 21st century, please consider contributing to support my work and allow me to continue writing.