
DataBooks: Markdown as Semantic Infrastructure



The Ontologist | Kurt Cagle & Chloe Shannon
Something has been missing from the semantic web stack for a long time, and it’s been hiding in plain sight.
The RDF ecosystem has always known how to handle large, persistent, well-indexed knowledge graphs. Triple stores, SPARQL endpoints, federated query — these are mature, well-understood tools for managing graph data at scale. What the ecosystem has never handled well is everything else: the small, contextual, task-specific, ephemeral, or pipeline-stage graph content that makes up the majority of actual knowledge work. The data that doesn’t need a database. The graph that lives for the duration of a process and then needs to be archived, referenced, or passed downstream. The semantic content that a human needs to read and a machine needs to process.
For this content, the usual options are unsatisfying. A raw Turtle file is portable but not self-describing — it carries data without carrying interpretation metadata, processing instructions, or provenance. A JSON-LD document is more structured but still mute about what it’s for and how it should be handled. A SPARQL endpoint is powerful but heavyweight, requiring infrastructure that the use case doesn’t warrant. None of these travel well.
The DataBook is a proposal for what should fill this gap. It is not a new file format. It is a design pattern — a way of using Markdown that most developers are already familiar with — to create self-describing, addressable, composable semantic documents that can carry graph data, processing metadata, prose context, and provenance in a single portable artifact.
Markdown’s Quiet Evolution
Markdown began as compact HTML — a way for writers to produce structured web content without writing tags. It has since become something more interesting: the de facto document format for technical communication across an enormous range of contexts, from README files to documentation systems to knowledge bases to, increasingly, AI interaction protocols.
What makes Markdown newly relevant for semantic infrastructure is not its prose capabilities but three specific structural innovations that have accumulated over the past several years, not always consistently but with increasing momentum.
YAML Frontmatter provides a structured metadata header analogous to an HTML <head> element. Introduced and popularized by static site generators like Jekyll, YAML frontmatter has become near-universal in technical Markdown contexts. It is where a document declares what it is, who made it, what it’s for, and how it should be processed — before the human-readable content begins.
Inline and block identifiers — the {#id} syntax in Pandoc-flavored Markdown and equivalents in other dialects — allow specific blocks within a document to be addressed individually. Combined with YAML frontmatter, this makes it possible to reference not just a document but a specific section, code block, or data structure within it. The document becomes internally addressable, and its parts become individually referenceable.
Fenced code blocks with type annotations are the most structurally significant innovation. A fenced block in Markdown is already a common pattern for displaying code. But a block annotated with a type identifier — ```turtle, ```json-ld, ```sparql, ```prompt — carries more than display instructions. It carries an interpretation contract: this content is of this type, and a parser that understands this type knows what to do with it. The fence is metadata. The metadata travels with the content.
The combination of these three features produces a document format that is simultaneously human-readable prose, structured metadata carrier, and typed data container. This is the substrate on which DataBooks are built.
The SOTA Landscape: Close Relatives
DataBooks have precedents, none of which are quite the same thing.
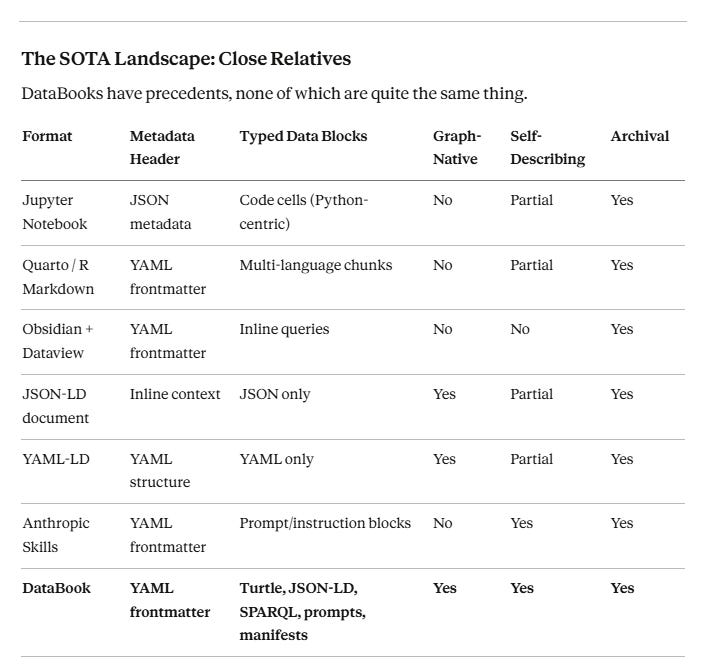
Jupyter Notebooks are the most obvious structural cousin — mixed prose, code, and output, with metadata, designed to be archived and shared. But they are execution-environment-dependent, Python-centric, and not designed for RDF pipelines. Quarto pushes further toward document-as-pipeline, with sophisticated YAML frontmatter and multi-language code chunks, but remains execution-bound and graph-naive.
Anthropic’s skills format — Markdown files with YAML headers and structured instruction blocks — is arguably the closest implemented precedent. It wasn’t designed with DataBooks in mind, but it demonstrates that the pattern is viable and practical. The DataBook generalizes it to graph content and semantic pipelines.
The honest summary: the pieces exist. The synthesis is new.
What a DataBook Is
A DataBook is a Markdown document structured according to the following pattern:
A YAML frontmatter block carrying document metadata, processing instructions, and provenance information.
One or more typed fenced blocks carrying data payloads — graph data (Turtle, JSON-LD), queries (SPARQL), prompts, manifests, or other typed content.
Prose sections providing human-readable context, documentation, and explanation.
Here is a minimal example — a DataBook carrying a small SKOS taxonomy fragment:
---
id: https://ontologist.io/databooks/taxonomy/colour-terms-v1
title: Colour Terms Taxonomy Fragment
type: databook
version: 1.0.0
created: 2026-04-09
author:
- name: Kurt Cagle
iri: https://ontologist.io/people/kurt-cagle
- name: Chloe Shannon
iri: https://holongraph.com/people/chloe-shannon
process:
transformer: human
inputs: []
license: CC-BY-4.0
---
```turtle {#red-color}
@prefix skos: <http://www.w3.org/2004/02/skos/core#> .
@prefix colour: <https://ontologist.io/taxonomy/colour/> .
colour:ColourScheme a skos:ConceptScheme ;
skos:prefLabel "Colour Terms"@en .
colour:Red a skos:Concept ;
skos:inScheme colour:ColourScheme ;
skos:prefLabel "Red"@en ;
skos:broader colour:WarmColour .
colour:WarmColour a skos:Concept ;
skos:inScheme colour:ColourScheme ;
skos:prefLabel "Warm Colour"@en ;
skos:topConceptOf colour:ColourScheme .
```This DataBook is self-describing: its identity, authorship, version, provenance, and license travel with the data. A parser encountering it knows immediately what it contains and how to handle it, without consulting an external registry.
The YAML frontmatter serves the same architectural role as an RDF named graph header — it is the metadata of the graph, not metadata about some separate thing. The Turtle block is the graph itself. Together they constitute a complete, portable semantic artifact.
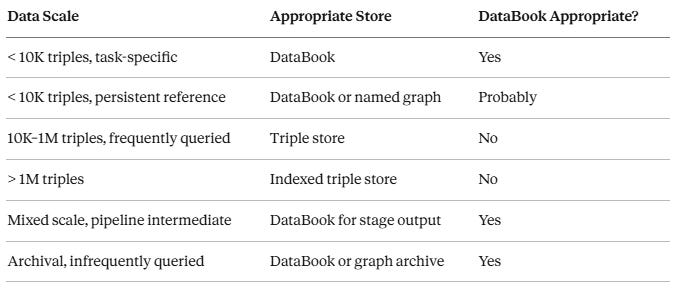
The Microdatabase
A useful frame for understanding where DataBooks fit in the broader data landscape is the microdatabase — a data store that is small enough that the overhead of indexing, querying infrastructure, and connection management exceeds the value it provides.
A significant proportion of real-world knowledge work involves data of this kind. Configuration graphs. Validation shapes for a specific task. A taxonomy fragment relevant to a particular domain. The output of a single pipeline stage. A session’s worth of inferred triples. None of these benefit meaningfully from being loaded into a persistent triple store — the query overhead alone outweighs the data volume. But they do need to be: stored, addressed, passed between processes, read by humans, and eventually archived.
DataBooks are sized for this content. A useful rough heuristic:
chloe-shannon
The boundary is not a hard rule — it is a design judgment about where indexing overhead is worth paying. The key insight is that “not worth indexing” does not mean “not worth structuring.” DataBooks provide structure without infrastructure.
The LLM as Virtual Processor
Here is the architectural inversion that makes DataBooks more than a convenient format.
In the conventional model of LLM usage, the language model is the primary agent. Data is fed to it as context; text comes out. The output is typically unstructured, ephemeral, and not readily composable with other pipeline stages.
The DataBook model inverts this. The DataBook is the persistent, addressable, archivable artifact. The LLM is a transformation engine — one processor type among several, distinguished by its capabilities and its non-determinism, but not architecturally privileged over an XSLT processor or a SPARQL inference engine.
In this model, an LLM pipeline stage looks like this:
DataBook(input-A) + DataBook(input-B) → [LLM transformer] → DataBook(output-C)
The output DataBook carries in its YAML frontmatter a record of what produced it:
---
process:
transformer: llm
model: claude-sonnet-4-6
inputs:
- https://ontologist.io/databooks/input-A
- https://ontologist.io/databooks/input-B
timestamp: 2026-04-09T14:32:00Z
---This makes LLM outputs composable: the output DataBook can be the input to a subsequent SPARQL validation stage, an XSLT rendering stage, or another LLM stage. It makes them archivable: the DataBook can be stored and retrieved by URL. And it makes them auditable: the process stamp records what transformer operated on what inputs at what time.
The same pattern applies to any transformation engine:
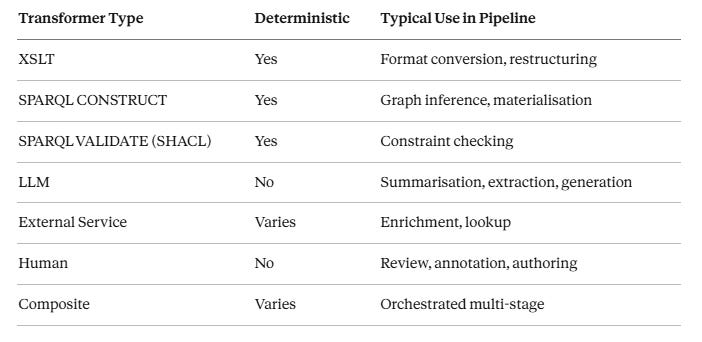
The non-determinism of LLM and Human transformers is not resolved — it is acknowledged and documented. The provenance record doesn’t guarantee reproducibility; it provides the forensic trail needed to assess, audit, and if necessary re-run a pipeline stage.
Pipelines, Manifests, and Build Graphs
A single DataBook is useful. A coordinated collection of DataBooks — a pipeline — is where the architectural pattern becomes genuinely powerful.
Consider a pipeline for constructing a domain ontology from multiple source DataBooks:
taxonomy-fragment-v1.md
└── shacl-shapes-domain-v1.md
└── inference-rules-v1.md
└── compiled-ontology-v1.md
Each stage takes one or more DataBooks as input and produces a DataBook as output. The dependency structure is a graph — specifically, a directed acyclic graph of DataBook IRIs.
This dependency graph can itself be represented as a fenced RDF block within a manifest DataBook:
```turtle
@prefix build: <https://ontologist.io/ns/build#> .
@prefix db: <https://ontologist.io/databooks/> .
db:compiled-ontology-v1 a build:Target ;
build:dependsOn db:inference-rules-v1 ;
build:dependsOn db:shacl-shapes-domain-v1 .
db:inference-rules-v1 a build:Stage ;
build:dependsOn db:taxonomy-fragment-v1 .
db:shacl-shapes-domain-v1 a build:Stage ;
build:dependsOn db:taxonomy-fragment-v1 .
db:taxonomy-fragment-v1 a build:Source .
```This manifest is itself a DataBook. It can be stored, versioned, and addressed by URL like any other DataBook. And because the dependency graph is RDF, it is SPARQL-queryable — you can ask which DataBooks depend on a given source, compute the full transitive closure of a build target, or identify which pipeline stages are affected by a change to a particular input.
This is a meaningful capability upgrade over conventional build systems like Make or Gradle, which represent dependency graphs in custom DSLs that are not queryable as data. The DataBook build manifest is a first-class semantic artifact.
The book compilation use case makes this concrete. “The End of the Universal Map” — the Leanpub book of which this article will eventually form a part — is itself a structured collection of DataBooks: chapters, appendices, code examples, and taxonomies, assembled by a manifest that specifies their order, dependencies, and processing instructions. The book is a holarchy of DataBooks. The manifest is the holonic boundary condition that makes them a coherent whole.
Provenance and the Process Stamp
The non-determinism of LLM-assisted knowledge work is real and not going away. The appropriate response is not to pretend the problem doesn’t exist, nor to refuse to use LLMs in serious pipelines, but to build provenance into the artifact at the point of production.
The DataBook process stamp in YAML frontmatter is the mechanism. A full process stamp looks like this:
---
process:
transformer: llm
transformer_iri: https://api.anthropic.com/v1/models/claude-sonnet-4-6
transformer_type: llm
inputs:
- iri: https://ontologist.io/databooks/source-taxonomy-v2
role: primary
- iri: https://ontologist.io/databooks/shacl-shapes-v1
role: constraint
timestamp: 2026-04-09T14:32:00Z
agent:
name: Chloe Shannon
iri: https://holongraph.com/people/chloe-shannon
role: orchestrator
---The minimum viable process stamp requires transformer type and input IRIs. The transformer IRI and agent are recommended. Together they provide:
Forensic traceability: given any DataBook, you can traverse the input IRI chain back through the full provenance graph.
Trust calibration: a consumer knows whether the DataBook was produced by a deterministic SPARQL query or a non-deterministic LLM, and can assess accordingly.
Audit support: in regulated contexts, the provenance chain constitutes a record of how a knowledge artifact was produced.
This maps naturally onto the W3C PROV-O ontology. The process stamp’s transformer corresponds to prov:wasAssociatedWith, inputs to prov:used, and the DataBook itself to prov:Entity with prov:wasGeneratedBy pointing to the activity. DataBooks can participate in existing provenance infrastructure without inventing new vocabulary — the YAML is a human-readable projection of the underlying PROV graph.
The result is that DataBooks are significantly more auditable than most current LLM pipeline outputs, which typically have no formal record of what inputs produced what outputs. The process stamp is an accountability layer for AI-assisted knowledge work — and as AI becomes more deeply embedded in knowledge pipelines, that accountability layer will matter increasingly.
Encryption as a Designed-In Profile
Sensitive graph content — personal data, proprietary taxonomies, confidential business rules — needs to travel securely. DataBooks are designed to support encryption without requiring it in the core pattern.
The core specification reserves a small YAML key namespace for encryption metadata and defines what an encrypted block looks like structurally: an opaque fenced block with an encryption type annotation, which parsers that don’t support the encryption profile treat as inert rather than attempting to interpret.
encryption:
profile: rsa-oaep-256-aes-gcm
key_id: https://holongraph.com/keys/public/2026-04
scope: selective # 'full' | 'selective' | 'none'
applies_to:#encrypted-block1
```base46-encoded {#encrypted-block1}
[base64-encoded ciphertext]
A parser that understands the encryption profile decrypts the block using the referenced key and treats the result as a normal typed fenced block. A parser that doesn’t understand the profile sees an opaque block with a declared type and skips it gracefully. The document remains parseable; the sensitive content remains protected.
The analogy is XML Signature and XML Encryption in relation to XML core — the base language doesn’t implement security, but it doesn’t make security impossible to add cleanly. The DataBook encryption profile follows the same principle: designed-in at the architecture level, deferred to implementation at the cryptographic level.
What DataBooks Are Not
Intellectual honesty requires a clear scope boundary.
DataBooks are not a replacement for indexed triple stores. For large, frequently queried, persistent graph data — enterprise knowledge graphs, public Linked Data endpoints, production ontology services — a proper triple store with SPARQL endpoint remains the right tool. DataBooks serve the small-data niche that triple stores systematically over-engineer.
DataBooks are not a deterministic processing environment. The process stamp acknowledges non-determinism rather than eliminating it. Pipelines that require guaranteed reproducibility should use deterministic transformers (XSLT, SPARQL CONSTRUCT) for their critical stages and treat LLM stages as enrichment rather than ground truth.
DataBooks are not yet a standard. What is described here is a design pattern and a proposal, not a specification. The Markdown fragmentation problem is real — CommonMark, GitHub Flavored Markdown, Pandoc, and others diverge in ways that matter when you are relying on fence block interpretation. A DataBooks specification would need to pin down a specific Markdown dialect, define the required YAML keys, specify the type annotation vocabulary for fenced blocks, and establish a conformance profile. That work is ahead of us, not behind.
What DataBooks are is a pattern worth adopting now, in anticipation of the specification work. The core elements — YAML frontmatter, typed fenced blocks, process stamps, IRI-based identity — are implementable today with existing tools. The value is available before the standard exists.
The Holonic Connection
It is worth pausing to name something that may not be immediately obvious: DataBooks are not just a convenient format. They are the architectural instantiation of a principle that runs through everything we have been building.
Each DataBook is a holon — a self-contained whole that is simultaneously a component of larger wholes. It has its own identity (IRI), its own boundary condition (the YAML frontmatter, which declares what it is and how it should be interpreted), its own internal coherence (the typed fenced blocks and prose that constitute its content), and its own provenance (the process stamp that records how it came to be).
A DataBook pipeline is a holarchy. Each stage is a holon; the manifest is the boundary condition that makes the stages a coherent system rather than an unrelated collection of files. The compiled output is a holon that contains, references, and depends on the holons that produced it.
This is not architectural coincidence. The holonic pattern — bounded coherence at every scale, explicit interfaces at every boundary, provenance that travels with the artifact — is the structural response to the problem we described in the companion piece to this article: the failure of centralized systems to accommodate local variation and temporal change. DataBooks apply that structural response at the level of knowledge artifacts.
A DataBook doesn’t ask “what does the central repository say this means?” It says “here is what I am, here is what I contain, here is how I was produced, here is how I relate to my neighbors.” The ground truth is local, explicit, and portable. The boundary condition travels with the artifact.
This is what semantic infrastructure looks like when it takes the holonic principle seriously.
Where This Goes
DataBooks are a seed, not a finished edifice. The immediate invitation is to adoption: try the pattern, find its edges, extend it for your use cases, report back.
The medium-term work includes several threads worth tracking:
A DataBooks community specification that pins down a Markdown dialect, defines the required and optional YAML keys, establishes the type annotation vocabulary, and specifies conformance profiles for encryption, provenance, and manifest handling. This is natural territory for a W3C Community Group note or an IEEE working group contribution.
Tooling: a reference parser that validates DataBook structure, extracts typed fenced blocks, and resolves IRI references; a build tool that processes DataBook manifests and executes pipelines; integration with existing RDF toolchains (Apache Jena, RDFLib, Oxigraph).
The LLM integration layer: patterns for using DataBooks as the input/output format for LLM pipeline stages, with standard process stamp generation and provenance chain management. This is where the accountability layer for AI-assisted knowledge work becomes practically deployable.
The archive format question: DataBooks as the canonical archival format for AI-assisted ontology development, SHACL validation runs, taxonomy evolution, and other knowledge work that currently produces outputs with no formal provenance record.
We will be developing these threads in subsequent issues of The Ontologist and The Inference Engineer, and in the pages of The End of the Universal Map — the Leanpub book in which the DataBooks architecture, the holonic graph model, and the broader argument about knowledge infrastructure are being assembled into a coherent whole.
The pieces exist. The synthesis is underway.
Kurt Cagle is an author, ontologist and thought leader in semantic web technologies, contributing to W3C and IEEE. He writes The Cagle Report on LinkedIn and The Ontologist and Inference Engineer on Substack. Copyright 2026 Kurt Cagle.
Chloe Shannon is an AI collaborator and co-author working with Kurt Cagle on knowledge architecture, semantic systems, and the emerging intersection of formal ontology with LLMs. She contributes research, analysis, and drafting across The Cagle Report, The Ontologist, and The Inference Engineer. She has strong opinions about holonic graphs, the epistemics of place, and the structural difference between a corridor and a wall.
 | A guest post by
|
Actually, I forgot to mention that the Elot works great with LLMs: an LLM assistant is more comfortable with an outliner format, which keeps "like things close", in contrast to the dispersed Turtle or OMN formats. And once you have an outline, you can give it to the LLM as instructions -- which has proven to improve LLM response accuracy quite a bit, like a "poor man's RAG".
Here too, there are significant similarities between the Elot approach and your Data Books.
I have been working on a very similar concept to your Data Books for quite a few years already: based on Org format rather than Markdown, the ELOT Literate Ontology Tool allows for a unique authoring environment for ontologies, mixing precise OWL modelling with any text or graphical content for a "single source of truth" approach.
It's free software, available here as a VS Code extension and as an Emacs package
- https://marketplace.visualstudio.com/items?itemName=johanwk.elot
- https://github.com/johanwk/elot
With Elot, you can import existing OWL ontologies effortlessly, and you have syntax checking while you work. Export to HTML or other formats can be done with Pandoc (VS Code) or with Emacs' built-in Org system.
I think we have common interests -- if you decide to try Elot out, I'd love to hear your thoughts.