
Context Graphs: Free Association, Consistency, Narratives & Truth
Philosophical ramblings about the nature of narrative and context


This is a “think” piece, more the process of exploring ideas in my own head rather than trying to explain ideas to others. As such, it’s a bit on the rambling side, but I hope that it nonetheless provides value to you, gentle reader.
I had an online conversation earlier with Yau about context graphs (and other things) that helped crystallise some thoughts I’ve had floating subconsciously for a while now, concerning free association, consistency, and truth.
What exactly does a large language model do? It’s been called a transformer, but that describes anything that takes an input and produces an output. I don’t believe that an LLM is sentient in any meaningful sense of the word, primarily because it doesn’t really have a memory on which to build long-term; it has no formal world model that changes in response to its own actions. This is a problem with anything built on the Transformer architecture, by the way. You can argue that with RAG, this changes things somewhat regarding memory, but this, in turn, points to the reality that the LLM, by itself, is at best only a component of a larger system. I want to address this point here in just a bit, but let me carry this thread to its conclusion first.
The closest analogy I can find to an LLM is free association: LLMs daydream. This is a bit of anthropomorphisation, yes, but I think it’s a useful way to see where an LLM’s role in an architecture really is. In free association, one idea triggers another. Sometimes that thread leads nowhere, and you have to abandon that pathway and see what other pathways exist. Free association can be thought of as semi-random diffusion across a graph, guided by contextual constraints. The more constraints, the fewer and usually more well-defined the associated subgraphs.
Why is this useful to computation? It has to do with the fractal nature of information. We have become used to thinking of data as structured, but the reality is that most information about the world does not have a nice, clean, navigable structure; it is locked up in conversations, transcripts, writings, code, speeches, and so forth. Most information about the world is narrative, and it takes energy to extract and structure it into a form that can be processed more readily.
Of Narratives and Graphs
As I’ve written elsewhere, a narrative is the compressed serialisation of a sentence graph, based on functional units that we can abstractly refer to as tokens. Tokens could be words, but they could also be phrases or even larger structures. When you take that set of tokens and connect them so that they generally move forward, what emerges is a graph. Put enough of these graphs together, and you get a narrative fractal. You can even assign weights or probabilities that determine the strength of particular connections, creating Bayesian graphs. This isn’t a completely accurate description of a latent space, but it’s a very useful approximation.
For instance, the prompt:
Once upon a time in a land far away, there lived a beautiful princess named Zelda, who had beautiful blonde hair and fair skin, with big, blue eyes.will generate a narrative tree:
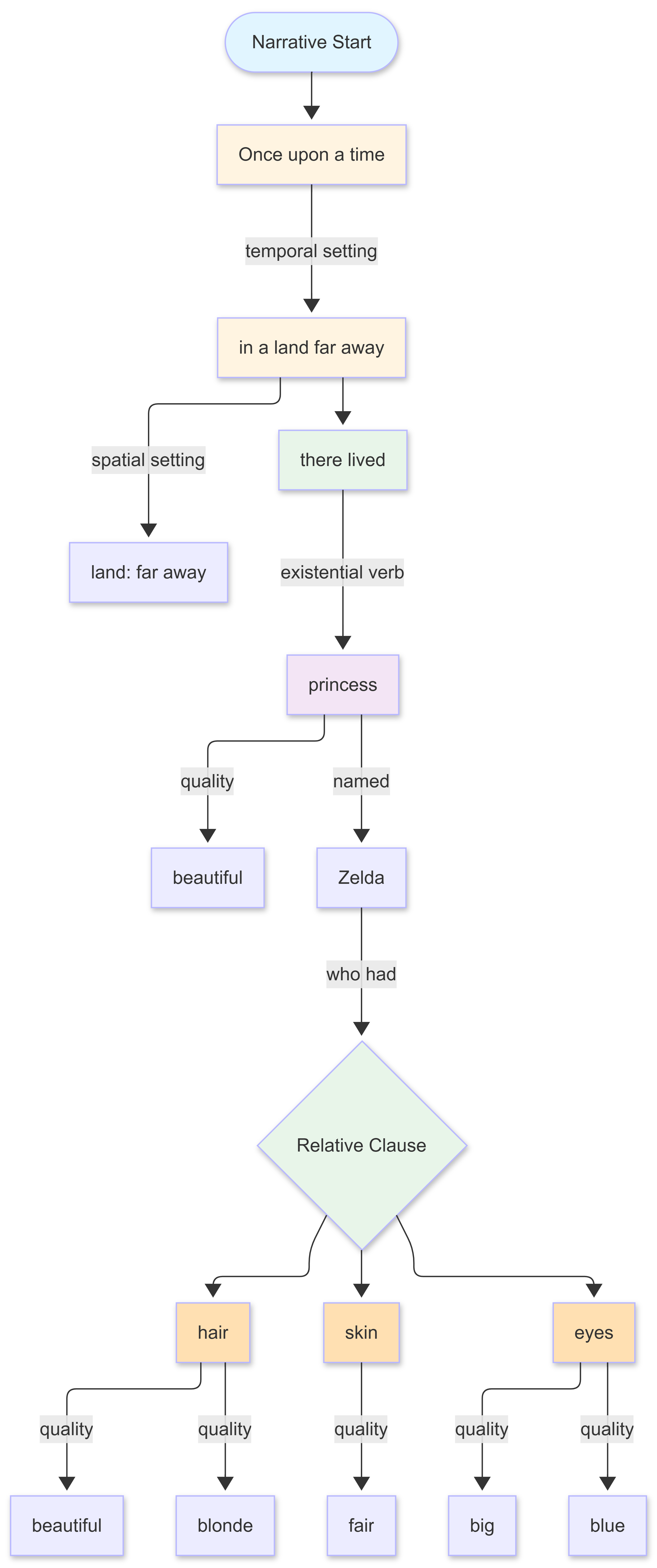
If then pass a prompt into a langchain, it will convert the prompt into tokens, vectorise it, find the threads that most closely align with that vector, and then attempt to match the resulting subgraph with the associated tokens in the same order. It may not find a perfect match, but it will (probably) get a set of result narratives with the highest potential scores for matching. The result is a form of free association, and because language is constructed in a particular way, what it returns can often be highly informative.
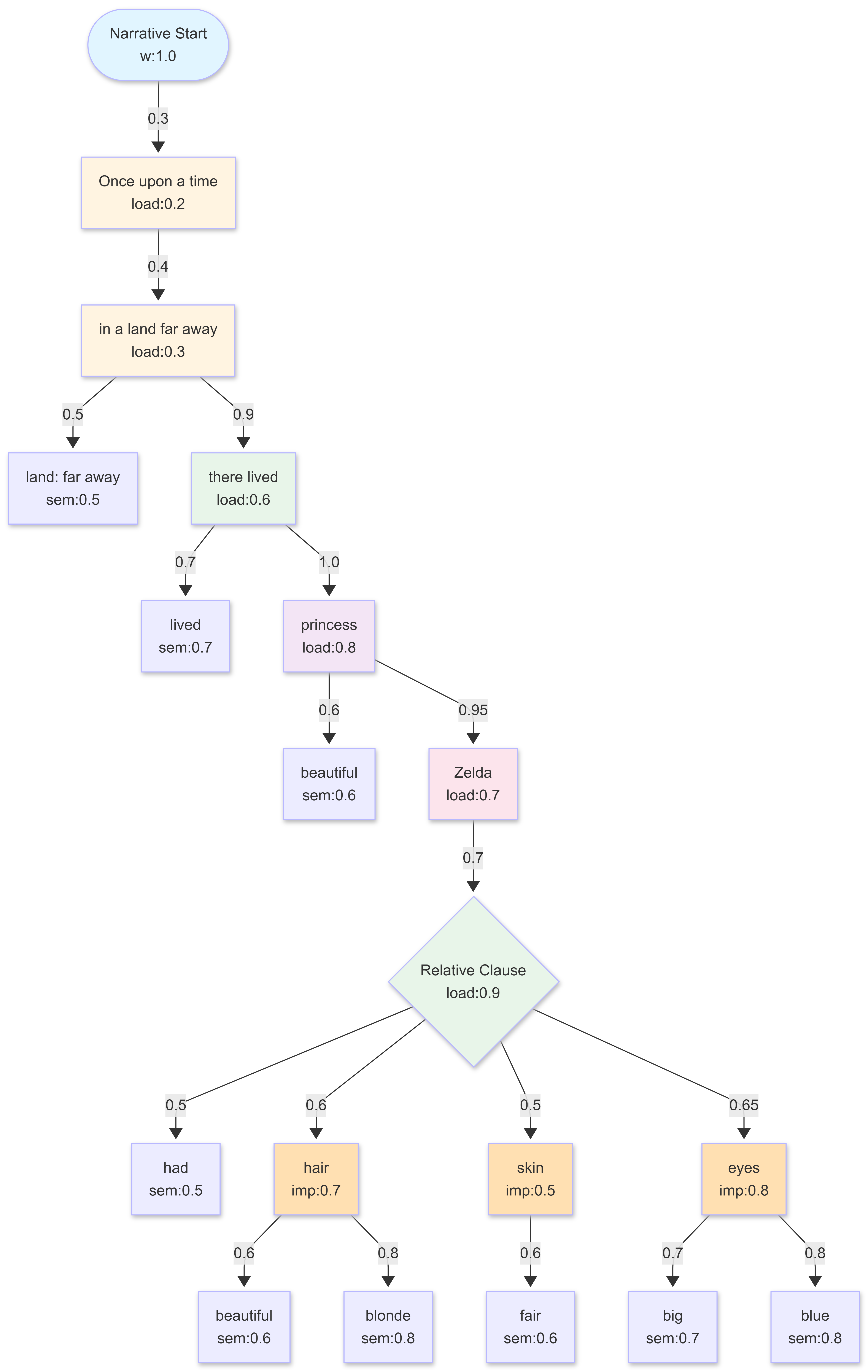
The weights can be understood as follows:
Weight Interpretation:
narrativeWeight (w): Story progression importance (0.0-1.0)
Princess = 1.0 (central character)
Name “Zelda” = 0.95 (key identifier)
Setting elements = 0.3-0.4 (context only)
cognitiveLoad (load): Processing complexity (0.0-1.0)
Relative clause = 0.9 (most complex structure)
Princess + name = 0.7-0.8 (character construction)
Temporal frame = 0.2 (formulaic)
semanticWeight (sem): Meaning contribution (0.0-1.0)
Color qualities (blonde, blue) = 0.8 (distinctive)
Verbs and modifiers = 0.5-0.7 (structural)
featureImportance (imp): Physical feature salience (0.0-1.0)
Eyes = 0.8 (most expressive)
Hair = 0.7 (visually prominent)
Skin = 0.5 (baseline description)
These weights could be used for narrative generation ordering, summarisation priority, or information retrieval ranking.
What it doesn’t guarantee is consistency. Remember the note about Bayesians? The connection between two tokens may be weighted based on external facts. If you place no weighting on the connections, when you put in a prompt, you will get only those responses back that exactly match the prompt, but because few prompts are exactly the same as the encoded contents, getting the closest match is likely to provide no answers most of the time, and a very limited subsets of potential answers the rest of the time.
The Pachinko machine that makes up an LLM incorporates a randomiser that increases the range of acceptable dialogues served up by the LLM, primarily by looking upon each Bayesian value as a roll of the dice (the actual process involves clustering and partitioning a high-dimensional information manifold using tensors, but the effects are similar). The parameter that determines how much the guidance on the probabilities affects the weight of the chosen conversations is called the model's temperature. The higher the temperature, the richer the conversational matches, but the more likely the result will contain one or more irrelevant threads. These are called hallucinations.
Hallucinations are the cost of doing business with LLMs. Turn the temperature down to zero, and you may not get anything back beyond the prompt that you put into the langchain in the first place. Set the temperature too high, and the LLM free-associates all over the place, picking up all kinds of interesting conversational threads that may have absolutely no relevance to what you were looking for.
Sometimes, this is precisely what you want, because you don’t know what the information space really looks like. You can refine your queries after the initial prompt, which produces additional information that better constrains the output. Put another way, most LLMs treat the human brain as another filter, responsible for creating prompts based on its responses. This is one reason LLMs can be effective at refining ideas or thoughts, with the caveat that what you get back will largely reflect what you put in.
Knowledge graphs, as most people envision them, are usually considered atemporal, reflecting the state of knowledge about things at a particular point in time.
The above can be articulated as a knowledge graph:
@prefix : <http://example.org/narrative#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
# Core character entity
:Zelda a :Princess, :Character ;
rdfs:label "Zelda" ;
:name "Zelda" ;
:title "Princess" ;
:beauty "beautiful" ;
:hairColor "blonde" ;
:hairQuality "beautiful" ;
:skinTone "fair" ;
:eyeColor "blue" ;
:eyeSize "big" ;
:livedIn :FarLand ;
:existenceTime :OnceUponATime ;
:narrativeRole "protagonist" .
# Location entity
:FarLand a :Location ;
rdfs:label "a land far away" ;
:locationType "land" ;
:distance "far away" ;
:narrativeFunction "story_setting" .
# Temporal context
:OnceUponATime a :TemporalContext ;
rdfs:label "Once upon a time" ;
:temporalType "indefinite_past" ;
:narrativeFunction "story_opening" .
# Physical features as grouped entities
:Zelda_Hair a :HairFeature ;
:belongsTo :Zelda ;
:color "blonde" ;
:quality "beautiful" .
:Zelda_Skin a :SkinFeature ;
:belongsTo :Zelda ;
:tone "fair" .
:Zelda_Eyes a :EyeFeature ;
:belongsTo :Zelda ;
:color "blue" ;
:size "big" .
# Simple relationship assertions
:Zelda :hasHair :Zelda_Hair ;
:hasSkin :Zelda_Skin ;
:hasEyes :Zelda_Eyes .
# Class definitions
:Princess rdfs:subClassOf :Character ;
rdfs:label "Princess" .
:Character a rdfs:Class ;
rdfs:label "Character" .
:Location a rdfs:Class ;
rdfs:label "Location" .
:TemporalContext a rdfs:Class ;
rdfs:label "Temporal Context" .
:HairFeature a rdfs:Class ;
rdfs:subClassOf :PhysicalFeature ;
rdfs:label "Hair Feature" .
:SkinFeature a rdfs:Class ;
rdfs:subClassOf :PhysicalFeature ;
rdfs:label "Skin Feature" .
:EyeFeature a rdfs:Class ;
rdfs:subClassOf :PhysicalFeature ;
rdfs:label "Eye Feature" .
:PhysicalFeature a rdfs:Class ;
rdfs:label "Physical Feature" .This can be visualised as follows:
This is basically what most people think of when they hear knowledge graphs - structures that are timeless, yet if you start from the central character, you can effectively unspool the graph (serialise it, if you will) into the following narrative:
Princess Zelda, a beautiful character who serves as the protagonist, lived in a land far away once upon a time. She possessed beautiful blonde hair, fair skin, and big blue eyes.This is not ordered in the same way as the initial prompt, but it does contain the relevant information, including details for both temporal (“Once upon a time”) and spatial (“in a land far away”) contexts.
Put another way, because information is ordered within a graph based upon direction, most knowledge graphs do actually contain most of what is needed to describe a process, even when that process does not necessarily fit into the normal confines of Business nomenclature.
Note that this can be rearticulated as an event, with various entities :
@prefix : <http://example.org/narrative#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
# Event as first-class citizen
:LivingEvent a :ExistenceEvent, :Event ;
rdfs:label "Zelda lived in a land far away" ;
:eventType "existence" ;
:hasAgent :Zelda ;
:hasLocation :FarLand ;
:hasTime :OnceUponATime ;
:narrativeFunction "story_opening" ;
:sequenceOrder 1 .
# Character entity (participant in events)
:Zelda a :Princess, :Character ;
rdfs:label "Zelda" ;
:name "Zelda" ;
:title "Princess" ;
:beauty "beautiful" ;
:narrativeRole "protagonist" ;
:participatesIn :LivingEvent ;
:hasHair :Zelda_Hair ;
:hasSkin :Zelda_Skin ;
:hasEyes :Zelda_Eyes .
# Location entity (setting for events)
:FarLand a :Location ;
rdfs:label "a land far away" ;
:locationType "land" ;
:distance "far away" ;
:hostsEvent :LivingEvent .
# Temporal context (when events occur)
:OnceUponATime a :TemporalContext ;
rdfs:label "Once upon a time" ;
:temporalType "indefinite_past" ;
:framesEvent :LivingEvent .
# Physical features (states/properties of character)
:Zelda_Hair a :HairFeature ;
:belongsTo :Zelda ;
:color "blonde" ;
:quality "beautiful" .
:Zelda_Skin a :SkinFeature ;
:belongsTo :Zelda ;
:tone "fair" .
:Zelda_Eyes a :EyeFeature ;
:belongsTo :Zelda ;
:color "blue" ;
:size "big" .
# Class definitions
:Event a rdfs:Class ;
rdfs:label "Event" ;
rdfs:comment "First-class representation of something that happens" .
:ExistenceEvent rdfs:subClassOf :Event ;
rdfs:label "Existence Event" ;
rdfs:comment "Event representing a state of being or living" .
:Princess rdfs:subClassOf :Character ;
rdfs:label "Princess" .
:Character a rdfs:Class ;
rdfs:label "Character" ;
rdfs:comment "Agent that participates in events" .
:Location a rdfs:Class ;
rdfs:label "Location" ;
rdfs:comment "Place where events occur" .
:TemporalContext a rdfs:Class ;
rdfs:label "Temporal Context" ;
rdfs:comment "Time when events occur" .
:HairFeature rdfs:subClassOf :PhysicalFeature ;
rdfs:label "Hair Feature" .
:SkinFeature rdfs:subClassOf :PhysicalFeature ;
rdfs:label "Skin Feature" .
:EyeFeature rdfs:subClassOf :PhysicalFeature ;
rdfs:label "Eye Feature" .
:PhysicalFeature a rdfs:Class ;
rdfs:label "Physical Feature" .
# Event-centric properties
:hasAgent a rdf:Property ;
rdfs:label "has agent" ;
rdfs:comment "Links event to character performing or experiencing it" ;
rdfs:domain :Event ;
rdfs:range :Character .
:hasLocation a rdf:Property ;
rdfs:label "has location" ;
rdfs:comment "Links event to where it occurs" ;
rdfs:domain :Event ;
rdfs:range :Location .
:hasTime a rdf:Property ;
rdfs:label "has time" ;
rdfs:comment "Links event to when it occurs" ;
rdfs:domain :Event ;
rdfs:range :TemporalContext .
:participatesIn a rdf:Property ;
rdfs:label "participates in" ;
rdfs:comment "Links character to events they are part of" ;
rdfs:domain :Character ;
rdfs:range :Event .
:hostsEvent a rdf:Property ;
rdfs:label "hosts event" ;
rdfs:comment "Links location to events that occur there" ;
rdfs:domain :Location ;
rdfs:range :Event .
:framesEvent a rdf:Property ;
rdfs:label "frames event" ;
rdfs:comment "Links temporal context to events occurring within it" ;
rdfs:domain :TemporalContext ;
rdfs:range :Event .This maps as a diagram as follows:
And can be articulated as a narrative:
Once upon a time in a land far away, there lived a beautiful Princess named Zelda. She had beautiful blonde hair, fair skin, and big blue eyes.In essence, we’ve returned to the original prompt by focusing on the existential event as the starting point in our graph unwinding. The only real change is that we turned a subordinate phrase (starting with “who”) into a referential sentence beginning with “She”.
This re-articulation, based on events, is still a knowledge graph, but one in which events serve as the guiding relationships. Narratives are sets of interconnected events over time. I’d argue that this is a context graph, in the AI sense.
A transcript is a narrative of a single or multi-person conversation with embedded analyses, summaries, decision invocations, and corresponding actions. Its specific encoding can be articulated by a given schema (its ontology), which may already exist or be inferred from the characteristics of a narrative. For analysis purposes, creating a shared ontology becomes useful because it then makes it possible to handle (analyse) all of the narratives using the same fundamental terms and taxons (concepts), as well as to assign weights of various kinds to the narrative structures themselves.
I could stop here and mention SHACL and reifications (*cough cough*), but I won’t, at least not just yet.
Consistency, Causality and Truth
What differentiates the knowledge graph from the language model? Consistency. If I ask the knowledge graph for the narrative, it will return the same narrative every time, assuming the knowledge graph has not been updated with new information. If new facts are added to the graph, the structure remains consistent; only new content has surfaced.
An LLM, on the other hand, replaces deep context (information that may determine relevant narrative paths) with stochastic noise, because mathematically you are in effect trying to keep paths from getting stuck in quasi-stable loops. LLMs have MUCH deeper context stacks than knowledge graphs do, but because of that noisiness factor (especially when LLMS get to be, well, large) the deep context gets too smeared out and has to be approximated. These approximations limit the utility of LLMs as data stores (even before addressing issues of access cost or update frequency). Mathematically, LLMs will always be fuzzy and inconsistent because of this.
It is worth noting, however, that neither LLMs nor Knowledge Graphs can guarantee TRUTH. A narrative, regardless of how it is encoded, is epistolic in nature. An epistle in Greek (ἐπιστολή) is a letter or message containing a narrative or set of instructions; the term entered Latin as epistola. It is related to the Greek ἱστορία (history or story). Messages reflected the knowledge and awareness of the writer about a series of events, but there is no guarantee that such a writer was, in fact, a witness to those events, or that such events “really” occurred. Epistemic knowledge can then be seen as knowledge that has already been interpreted through biased lenses, filtered by limitations in language or access, and frequently derived from other stories.
An LLM is only minimally curated; training is done on a corpus of conversations, writings, and recordings, all of which are, by definition, epistolic. A knowledge graph is generally better curated, but that curation is intended to provide better consistency with other known assertions. It is still reliant on capturing events as close to the source as possible, to the extent that is manageable, without introducing too much editorialising that cannot be removed from the graph.
For instance, you can add metadata about intent within a conversation knowledge graph, but that metadata should be viewed as intrinsically subjective, depending on the commentator. An annotation in this regard is precisely such an opinion, and it actually reflects an event (a comment event) about a resource, not something that is intrinsic to the resource itself.
This is why, when dealing with historical data (which is most data, when you think about it), you can ascribe a likelihood that the assertions are valid - that they did occur - based upon internal consistency, but it is still a guess, only one that is more educated than may be the case elsewhere. This is something that ontologists and information architects SHOULD know but frequently forget, and that those unfamiliar with knowledge science should be more cognisant of.
No one has a monopoly on the truth.
This gets into the world of fiction. When a fiction author creates a story, they are building a world model that is not necessarily our world, but that nonetheless maintains a certain degree of internal consistency - it has a history, it has societal rules and behaviours, it has some form of technology (possibly disguised as magic), it has physics and weather patterns, and so on. Sometimes these are thin veneers, enough to suggest without getting too deep into the weeds; sometimes they are incredibly in-depth, but all fiction writers are building a consistent model as needed to carry the illusion of reality. They also usually signal that “the rules are different here”, that what is being represented is not intended to be a faithful representation of this world.
This is different from those who build conspiracy theories and deliberately craft falsehoods. The issue here is not that what they are saying is true or not (that’s a metaphysical distinction that’s remarkably difficult to prove) but rather that what they are saying is not consistent with other evidence.
It is this lack of consistency compared to other information that usually exposes falsehoods. This is why, in court trials, the jury is instructed to determine guilt or innocence beyond a reasonable doubt. If a witness’s statements seem contradictory to other evidence, what becomes important is determining how impeachable that witness really is. The scientific method is built on a similar foundation: a hypothesis is tested against known evidence, and if it explains or is consistent with that evidence, it is given greater weight. No hypothesis or theory is ever absolutely proved; it is only proved to the extent that no evidence is inconsistent with the hypothesis. When such inconsistencies do appear, then it is the theory, not the evidence, that needs to be modified.
Consistency, by the way, is very much influenced by context. This means that there is both structural consistency, an ontological schema that determines the shape of data, and a narrative or semantic consistency that consists of constraints from contextual data being satisfied. The latter can be seen as inference: if I have an assertion in my dataset that is aberrational based on other assertions (context), is it a bad assertion, such as corrupt data, or a significant outlier that indicates the model is wrong?
You can see this in practice with LLMs. It is my observation that LLMs, without guardrails, are actually pretty good about semantic consistency, even if they are all over the place with respect to structural consistency. Even when you feed an LLM clearly biased data, the nature of language models gravitates toward achieving some form of internal semantic consistency. This raw output tends to be unfiltered because, in the aggregate, language often has a sociopathic underpinning that is disguised by cultural overlays, but it is usually “honest” in its assessment and consistency.
When it becomes clearly biased (always saying only positive things about certain prominent political leaders or wealthy billionaires, for instance), this is almost certainly because the LLM has been modified with guardrails that compel it to “lie”, and even then, with the right prompts, the LLM slips the leash.
Another key point to consider regarding context graphs: causality. One frequently stated goal of a context graph is to provide a chain of antecedents showing that one decision caused another decision or action. Most trained historians learn early on that people prefer the notion of an ultimate cause, a sentimentBen Franklin echoed famous poem from Poor Richard’s Almanack:
“For the want of a nail the shoe was lost, For the want of a shoe the horse was lost, For the want of a horse the rider was lost, For the want of a rider the battle was lost, For the want of a battle the kingdom was lost, And all for the want of a horseshoe-nail.”

However, in practice, true causality is very difficult to prove, and at best, you can only claim influence instead. This is captured in the above graphic as well - the missing nail may have contributed to the loss of the kingdom, but ultimately, there were likely many other factors that ultimately also contributed to the loss of that kingdom, and that any analysis of decisions should look more at overall behaviour, not one isolated incidence. This is why capturing events becomes so very important.
A short analysis from Claude Sonnet:
Causality vs. Influence: The Horseshoe Nail Principle
The Poem’s Logic
The horseshoe nail poem presents a deterministic causal chain but illustrates disproportionate influence. A nail doesn’t directly cause kingdoms to fall - it occupies a critical position where its absence cascades through increasingly significant systems. The influence is asymmetric: trivial object, catastrophic consequence.
Business Decision Parallels
Similarities:
Minor decisions (skipping code reviews, cutting QA) cascade into major failures
Hidden dependencies reveal importance only retrospectively
We see causal chains clearly after disasters occur
Critical Differences:
Determinism vs. Probability: The poem’s chain is inevitable; business involves risk. Cutting QA increases failure likelihood but doesn’t guarantee it.
Reversibility: The poem assumes permanent losses at each step. Businesses can course-correct before cascades complete.
Multiple paths: The poem shows serial causality. Business failures result from convergent causality - multiple poor decisions creating failure conditions simultaneously.
Human agency: The poem is mechanistic. In business, people at each stage can amplify, dampen, or redirect consequences.
The Key Distinction
Causality asks: “Did A make B happen?” (binary, retrospective)
Influence asks: “How much did A change the probability of B?” (gradient, prospective)
The poem conflates these for didactic impact, presenting influence as causality to make the lesson stick.
In business, this conflation creates two errors:
Over-attribution: Blaming single decisions for complex outcomes
Under-appreciation: Ignoring how small decisions constrain future options
The takeaway: Poor decisions don’t cause failure - they make failure increasingly difficult to avoid. Mind the nails not because they determine outcomes, but because they narrow the space of possible futures.
One common claim about context graphs is that they also provide a control plane for future decision-making and, as such, constitute a proactive form of data governance, especially for AI-agentic bots.
I’m … ambivalent about this at best, not from a technical perspective but from a business architecture perspective. Technically, you can ensure that decisions that are made don’t commit to the graph if they cannot be validated, which means that something like SHACL’s sh:sparql (and the upcoming SHACL 1.2 rules) could be used to determine whether there are specific contextual limitations that need to be satisfied. This looks at the existing data fabric - what events have occurred in the past and been recorded.
It is possible (indeed, relatively easy) to create future events into such a system - you just need a way of indicating when they slip into the past (this is a very good use for node expressions, fwiw). The question is whether the forward generation of events, even in simulation, is necessarily a good practice. The problem is that the simulation you create in this manner operates on presumptive events, and as such, it increases the potential for surprise, as Karl Friston may posit, and the complexity inherent in adjusting your model (the future state) as you move forward.
I don’t think there's much difference between an LLM and a KG in such a forward evaluation, aside from the KG being likely faster, cheaper, and smaller, albeit with more rigid semantics. I don’t think that (at least semi-)rigid semantics is a bad thing; it means you’ve spent more time thinking about the model and the potential for surprise. A semantic model is a world model in this respect, and even surprises have to obey the laws of some form of physics.
Within the programming space, there is a fairly strong impulse toward imperative thinking. We expect our programs to “do” things, which is one reason we often build applications before data models. Doing things looks good on resumes and CVs, it wins grants and investment money, and it makes you look busy, busy, busy. I think this is the impulse behind control plans and context graphs, because knowledge graphs, even event-driven temporal graphs, don’t “do” anything.
Graphs are simply records of what has come, expectations of how data is shaped, constraints are kept, and context is formed; a grounding in common categories and terms; and annotations and ephemera that capture historical traces in the sand. This is declarative programming, a model of transitions between states driven by events, each captured as subgraphs. A context graph is a temporal, event-driven data fabric composed of numerous narratives that overlap and weave together, past, present, and even future, captured in its weft.
The question, ultimately, is where such fabric should reside. Concept graphs are unmistakably graphs; they are records of events and the things those events tie together. You can represent ambiguity in such graphs, but even that ambiguity is deterministic and quantifiable. It’s the difference between indicating an uncertainty in a hard record vs. rolling a die to select an option based on that uncertainty; the first is lossless, the second is lossy. Sometimes, lossy is fine - it’s (arguably) more compact. I’m just not comfortable with the notion that auditable trails should be lossy. To me, that’s a bad idea, because it sacrifices accuracy for speed - great for game design, hideously poor for legal records.
Let’s not overthink things.
In Media Res,

Check out my LinkedIn newsletter, The Cagle Report.
I am also currently seeking new projects or work opportunities. If anyone is looking for a CTO or Director-level AI/Ontologist, please get in touch with me through my Calendly:
If you want to shoot the breeze or have a cup of virtual coffee, I have a Calendly account at https://calendly.com/theCagleReport. I am available for consulting and full-time work as an ontologist, AI/Knowledge Graph guru, and coffee maker. Also, for those of you whom I have promised follow-up material, it’s coming; I’ve been dealing with health issues of late.
I’ve created a Ko-fi account for voluntary contributions, either one-time or ongoing, or you can subscribe directly to The Ontologist. If you value my articles, technical pieces, or general reflections on work in the 21st century, please consider contributing to support my work and allow me to continue writing.