
All You Need is Context
Copyright 2025 Kurt Cagle / The Ontologist


I never really set out to be an historian - I'm not sure most people do. When you're a kid, you declare that you're going to be a doctor, an astronaut, or a fireman. It's rare, if not unheard of, for someone to declare, as a life's profession, that they are going to become an historian of this or that, I think in part, because history is something that you only really appreciate when you have developed a sense of time. History is a profession for the old.
I know that I am an historian because I ramble. Most people, especially in Western society, do not understand rambling, the seemingly nonsensical narrative that someone has where they jump from topic to topic without ever seeming to get to the point. If you ask a historian a question, they will more than likely pause for a bit, then may start a narrative, a story, in media res, Latin for "in the middle of things". That person is mindful of the question that you asked, but also understands that, in order to get a handle on a particular topic or event or theory, you need context. You need the whole story, if you will, because most events only make sense if you understand what went before.
Context is a remarkably elusive concept to nail down, something I've been struggling with for much of my adult life. Perhaps the most intuitive definition is that "context is the rest of the story", the tagline of commentator (and historian) Paul Harvey. It is that information that you need to know in order to make sense of a particular assertion, event, or person.
Western culture today is obsessed with speed, with the state of the world right now. We have idolized the art of the summary: I don't have the time; just give me the elevator pitch. This is partially a pose, of course: we equate status, importance, with being busy, with having no time for mundane things because time is money. We seek meaning, but that meaning remains elusive because we have things to do, people to see. Yet without context, without understanding the bigger story, we often fail to understand the complexities of the world and, as a consequence, make poor decisions.
Data is the record of the state of a system at a specific time and location. The single most significant word there is system. A system is a little slice of reality, a way of segmenting things into that which is meaningful to you and that which is not. If you are studying the flow of traffic in Seattle (the system), the condition of corn during the summer in Illinois is likely not to be relevant, but the traffic flow in nearby Bellevue may very well be.
Relevance is another one of those very ambiguous terms that seem to get more nebulous the more you try to pin it down. Something is relevant to you (this is a very subjective measure) if the change in the state of a particular actor in a system impacts that which you are studying (that which is in your system). Put another way, the system is dependent upon that actor in some way. This implies that relevancy and causality are related - either one is dependent upon the other in some way (causation) or both are dependent upon a third unknown agent (correlation).
Relevancy is often described as similarity, though these aren't quite the same things. The former indicates that two particular things have some form of relationship that is important to the system, though the exact details of that relationship may or may not be known, while similarity implies that there are a number of characteristics that two entities may have in common.
Euler’s Bridges
This provides a good segue to talk about context in terms of networks. A network provides a lattice that connects various things together. While networks have been known about since ancient times, most of the mathematics about networks really didn't emerge until the early 18th century with the work of Leonhard Euler.
To mathematicians, Euler is known for a great number of things - he was the first to quantify the concept of logarithms (the inverse of exponentiation), and he made the realization that if you allow the square root of negative one as a special type of number (usually signalled with the letter i, then the exponent of this number with a constant maps to a point on a circle). This discovery would lay the groundwork for both the electromagnetic revolution of the nineteenth century and the quantum and relativity revolutions of the twentieth, just as his work on exponents laid the foundation for both chaos theory and fractals.
Euler’s work on networks started out after an afternoon walk in his then home-town of Koenigsberg, Prussia (it would eventually end up in Russia a few centuries later). Koenigsburg sat at the junction of two rivers, which branched into a number of tributaries that over time had been forded with seven bridges. As he looked over the river from one of them, he wondered whether it was possible to start from any point in the city and complete a path that would cross each bridge once and only once to make it back to where one started.
What he eventually realized was that not only was the answer “no” for seven bridges, it was “no” for any odd number of bridges, regardless of where you started or what shape the surrounding land masses or islands were in. In other words, the answer had nothing to do with the geometry of the problem, and everything to do with the broader shape of the networks and its holes, even if those shapes were on odd geometries like donuts. This would in turn lay the foundations for both graph theory (which could also be called network theory) and the domain of topology (the study of shapes in Greek).
Context, Networks, and Knowledge Graphs
Some two hundred years later, mathematicians and computer scientists began to explore graphs as ways of thinking about algorithmic and data representations. Flowcharts were perhaps the oldest expression of such graphs, with the notion that the nodes (the connecting points) representing actions, while the edges represented sequence, or in the case of conditional expressions, routes (if the condition is true, do this, if its false, do that).
Mathematicians call these LDCGs - Labelled Directed Cyclic Graphs - which means that they are graphs or networks where each edge has a preferred direction and it is permitted for such graphs to have “cycles” within them. Without the cycles condition (called LDAGs, the A for acyclic), you can’t have cycles, which means that the graph will usually be represented as either a sequence or a hierarchy.
A knowledge graph can be thought of as a network in which each node (or knot, reflecting the nautical evocation of fishing nets) represents a thing or concept, and each edge or connection represents a route or relationship. This combination of nodes and edges can then be said to contain information, with each NEN set then representing an assertion.
There are two primary models for describing these networks - one in which the edge has a single label that describes the general relationships (generally referred to as RDF graphs, for Resource Description Framework), while the other has the two nodes each representing things while the edge is specific to just those nodes (what are called labelled property graphs, or LPGs). Without getting into two much depth, these two models can be losslessly transformed from one to the other, and as such their particular details are not immediately relevant to this discssion.
Knowledge graphs do not necessarily need to be fully connected, A graph in this regard is a distinct set of assertions (distinct in the sense that there are no duplicates in the set). There is no guarantee that everything is connected to everything else in any given graph, and typically if you just include direct object associations without any metadata, a graph will actually decompose into a lot of different graphs.
Where things get interesting is when you start to identify commonalities and “type” descriptions. For example, here’s a knowledge graph that contains three classes - musicians, instruments, and bands.
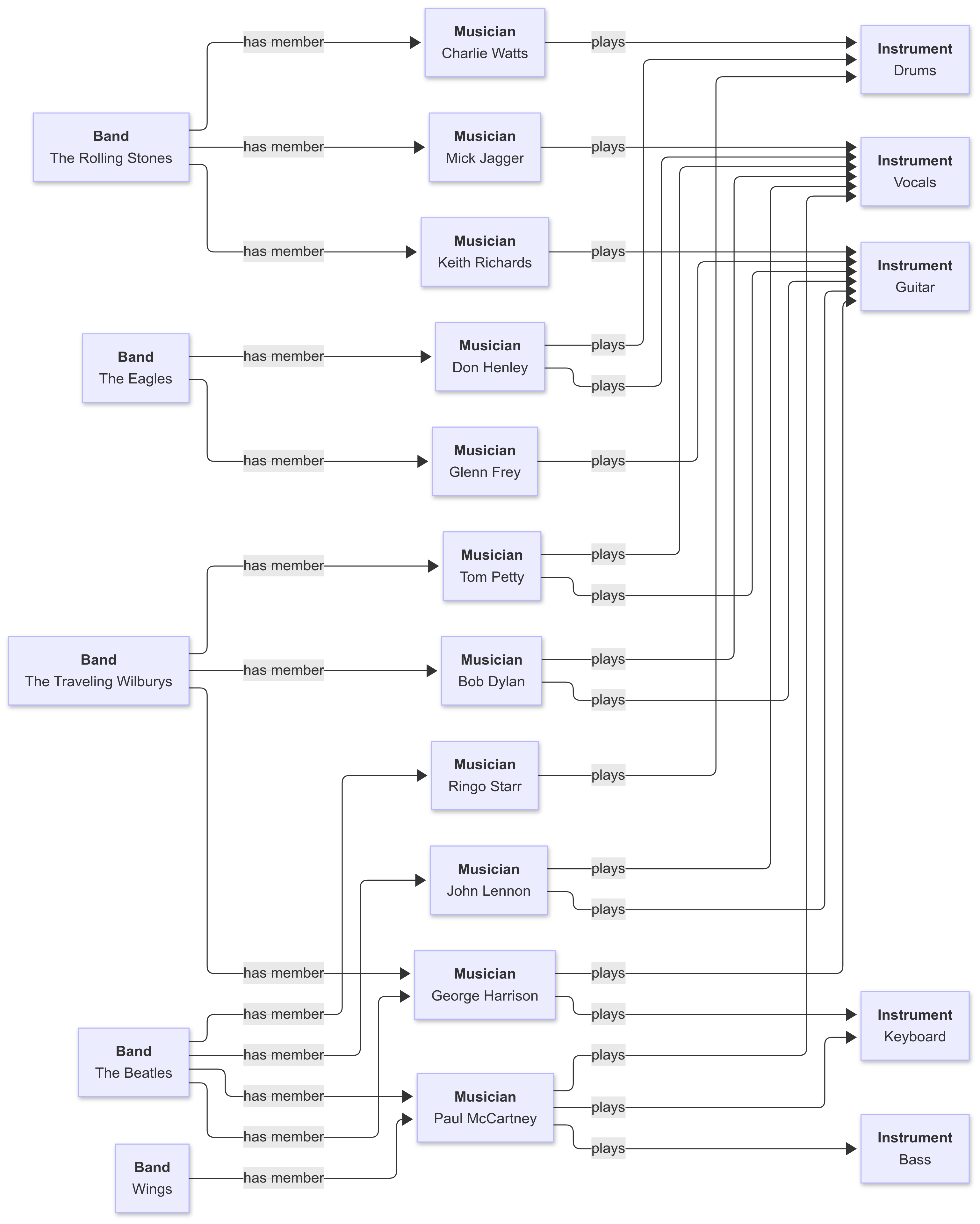
From the example given above, the context for any given musician can be determined by their links. For instance, George Harrison was in two bands - The Beatles and The Travelling Wilburies. He also played the electric guitar and was a vocalist. This is contextual information. What is not included is when he was in each band (as one example).
Context And Validity
This can of course be expanded, but involves looking at the graph temporally. For instance, Harrison was in each band at a different point in his career:
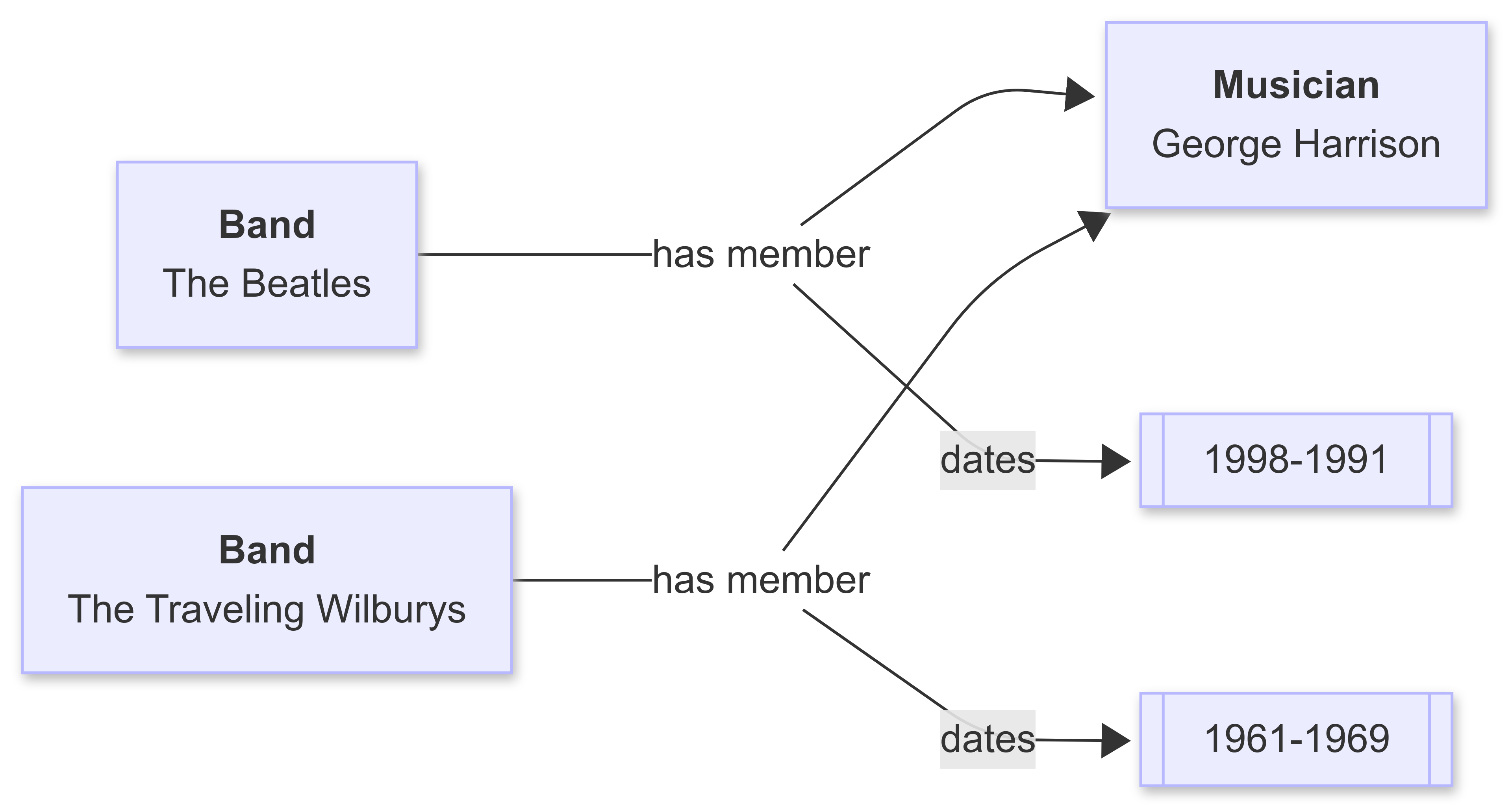
This graph needs a bit of interpretation. The property has member by itself doesn’t have the dates property. Rather the date is associated with the full statement (George Harrison’s tenure as a member of The Beatles). This is an example of a reification - an implicit rederence is created with an explicit subject and object across a given property, essentially a statement about a statement.
You could also model this as a graph with a Tenure object:
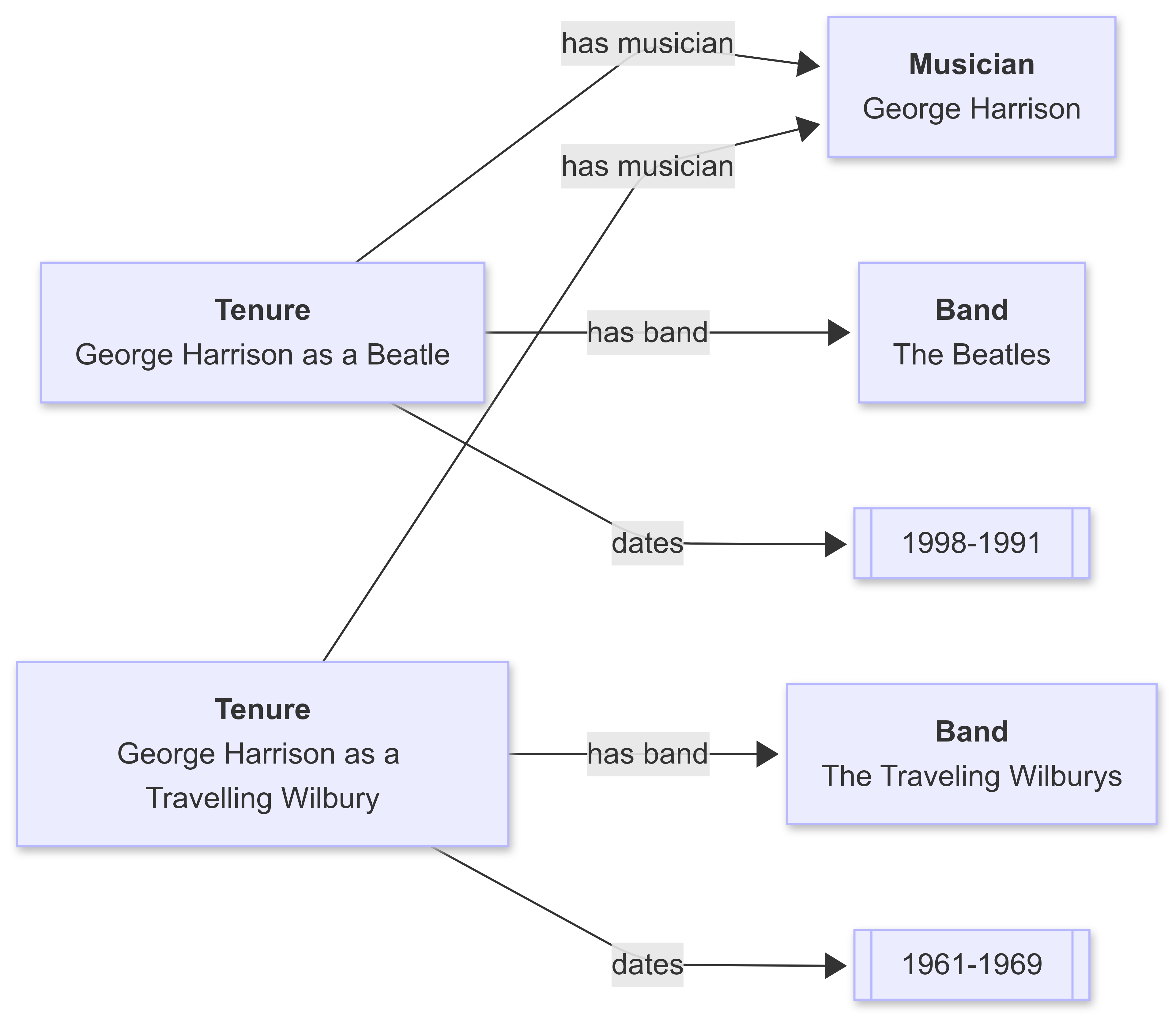
A reification can always be refactored as an explicit object of a given type (here a tenure), and most reifications tend to be events that establish a context that determine where the assertion is valid. George Harrison was a “Beatle” in 1965, but a “Traveling Wilbury” in 1990. He was neither of these in 1978.
This suggests an alternative definition of context: Context is information that can be used to determine when a particular statement is likely to be valid. This is a significant change in the way that we see the world, because it means that the data that we see is conditional and subject to interpretation. Historians understand this, of course. I have never met George Harrison, for instance, and cannot personally verify that he was in the Beatles in 1961, as an example, but I can read histories of people who have known him, during that period, can look at historical videos or contemporary interviews. None of these absolutely confirms that the statement is true, but it makes the likelihood of the statement true sufficiently high that it probably happened.
Note that in data modeling one of the most important decisions you’ll make will have to do with context.
For instance, in RDF, the property “is a” is an existential one - what is the context under which the resource in question is significant. George Harrison was a person (a live person) from 1943 to 2001. This is an existential statement about him that determines when he was viable. George Harrison as a concept will obviously extend beyond this (for instance, Harrison may have received an award posthumously). As a song writer, he may have written music at any point in his life, but afterwards he was too busy decomposing. Context is important.
There is also a distinction to be made between those actions that George Harrison did (he played guitar), vs., references to Harrison as an entity (he was a member of The Beatles). I like to break it done as those things that are intrinsic to the entity (such as when he was born, where he lived, and so forth), and those about the entity. The former are usually outbound relationships (Harrison as subject) while the latter are usually inbound relationships (Harrison as object).
Six Degrees of Kevin Bacon
Which is data and which is context? I find a good working definition is that, at least for a knowledge graph, context is inbound links (what others think about a thing), while data is what that thing knows about others. Put another way, context is dependent upon where you are in the graph.
An example may better elucidate this - consider the FOAF (friend of a friend) ontology. I know about George Harrison. He is, at least indirectly, an object of this particular essay. It is extraordinarily unlikely, however, that George Harrison knew anything about me. This is why you have to be very careful with understanding the flow of information. Context is not always symmetrical, because relevance is a factor in either direction.
Putting this into code (Turtle):
<Person:GeorgeHarrison foaf:knowsOf Person:KurtCagle> assertion:likelihood 0.01% . <Person:KurtCagle foaf:knowsOf Person:GeorgeHarrison> assertion:likelihood 99% .
Indeed, this can be seen in the old party game of Six Links to Kevin Bacon, in which the participants tried to identify six points of connection between a given person and actor Kevin Bacon. It turns out that, from a purely mathematical basis, the likelihood is high that anyone has some link across that many hops, but the links become very tenuous for most people: “My cousin is the hairdresser for the niece of the sister of a movie star who was in a movie with another actor who also starred with Kevin Bacon”.
What that suggests is that within any network, the strength of each connection plays a big part in the notion of relevancy. This makes physical sense - a major tributary is going to have more impact upon the flow of a river than a creek, for instance, and any two points in that river system will be “relevant” primarily to the extent that they tend to share common branching points.
To a significant extent, this is why "Kevin Bacon” is so important, while at the same time not being very significant at all. Kevin Bacon can be thought of as a path in time. During his day, he likely gets up, gets dressed, breaks his fast, does some work, comes home, spends some time resting and socializing, then goes to bed - in that respect he will do some variation of that over the course of his life, just like almost everybody on the planet.
It is the byproducts of his interactions, however, that make his life interesting. He makes movies - as an actor, writer, director, producer. A movie is a significant event both because it involves a lot of other people involved in a creative enterprise, and it is seen by a comparatively large number of people, who thus incorporate it, even if only indirectly, into their own timeline (they went to see that movie).
Perhaps a couple went to see that movie, that night had fabulous sex, which resulted nine months down the road in having a boy, whom they also called Kevin. For them, that particular movie (and its actors) thus has a profound influence, but that likely doesn’t really impact Kevin Bacon in any significant way.
There’s several things to take from this. First, of course, is the impact of time on all of this. There is likely a significant gap from the time that Kevin Bacon was involved in the production of any given movie and the time that the movie impacted others. In an era where a playing troupe moved from kingdom to kingdom, the event of a given performance was significant. With the emergence of media packaging and distribution (from books to streaming), the history (somewhat) gets lost - we can sample the works of Kevin Bacon or George Harrison in any order, but the likelihood of our direct interaction with his timeline is far smaller.
This also leads to categorization and conceptual expansion. We talk about the movies of Kevin Bacon, or the performances of George Harrison. Temporality is still important as an organizing principle, but so too are the forms of media, or the genre themes, or the intersections of the interactions of a given person with others (George Harrison as a Beatle vs. a Travelling Wilbury, as an example).
Networks, Trees, and Transitive Closures
The first exposure that most people have with ontologies is taxonomies. Indeed, language acquisition can be seen as the art of successive refinements in personal taxonomies. When you are a baby, your taxonomy is very limited, usually coming down to “What do I see, hear, taste or smell?” A newborn may get a sense of thingness, usually tied into sensory state: I’m hungry and cry, and someone sticks a nipple in my mouth. I’m full and I void, but that void is unpleasant and uncomfortable, so someone removes it by changing my diapers.
As they get older, babies began to build up associations - this is the one who sticks her nipple in my mouth, this is the one who carries me, this is the one that goes “meow” or “woof” and startles me. They begin to recognize categorical differences - these are my people, my pets, my toys, my food. Words come later, “mama”,”dada”, “baba”,”woof”, and eventually they get folded and categorized (mama is a person, baba is a drink, woof is an animal). Later yet, we differentiate - man/woman, milk/water/juice, dog/cat/fish, and refine those definitions - beagle, German shephard, cocker spaniel, etc.
A taxonomy is an organizational system of successive refinement. It is a network, in that you can navigate along a certain path to get to a thing, or (and this is in some respects more significant), you can go from a particular instance (a thing) up through successive layers of categorization along a particular dimension. fido/cocker_spaniel/dog/animal/living_thing/thing. An ontologist would say that such a taxonomy represents specificity (this thing is more specified than its parent, or, inversely, the parent is more generalized than the child).
There are other dimensions of taxonomies, however. For instance, consider teacher/student relationships (not that kind of relationship, though that’s happened as well). This is a form of influencer relationship - a teacher has several students, some of whom go on to be teachers of other students, to the extent that any given student is influenced by a chain of teachers, each of which taught a certain interpretation.
The student may not believe that interpretation, and in fact will likely not be in in complete accord with their teacher, in part because they have different experiences and in part because any student wants to differentiate himself from his teacher in some way. Nonetheless, such a lineage becomes important to both the student and to others in helping understand why a person believes what they do, as well as a way of creating indirect status (my teacher was better than your teacher).
The concepts of specificity and lineage are two examples of properties that exhibit the characteristic of transitive closures. You may remember transitivity from your beginning algebra class: an operator is considered transitive if it satisfied the following relationship:
if A is related to B and B is related to C then A is related to C for the same relationship.
For instance,
if a cocker spaniel is a kind of dog, and a dog is a kind of pet, then a cocker spaniel is a kind of pet.
Not all relationships are transitive. If you know Kevin and Kevin knows George, this does not imply that you know George. This is actually one of the flaws of the Six Degrees argument - to know, in the sense of having met, is not in fact a transitive relationship.
A closure, on the other hand, indicates the set of all nodes that share the same relationship and have a common ancestor node). For instance, the movie The Empire Strikes Back was inspired by Star Wars, which in turn was inspired (heavily) by Akira Kurasawa’s The Hidden Fortress, and by transitive closure, the entire Star Wars franchise can be said to be inspired by Kurasawa’s work - they are a transitive closure of The Hidden Fortress.
Transitive closures are trees, which in turn can be thought of as a particular form of network. They are very important from a contextual standpoint because membership within a transitive closure usually implies some form of relevance, and almost invariably also is a reflection of time (or more properly, causality).
You can see this in the grandfather of all taxonomies, the Linnaean Taxonomy of living creatures. On one hand, the original taxonomy was based primarily upon specificity - homo sapiens is a form of hominid, which is a form of ape, which is a form of monkey, which is a form of primate, which is a form of insectivore, which is a mammal. Yet there is implied in all of this that each step up the latter from homo sapiens also reflected an earlier common ancestor - there was an ur hominid, an ur ape, an ur mammal. That is to say, the Linnaean taxonomy is a causal mapping.
A document is a tree structure as well (we call this an outline). In this case, the outline represents the evolution of ideas, from the most general (the focus of the book), to the most specific (a particular scene in a novel or subsection in a textbook). It does not explicitly imply that the ordering of ideas in the book are temporal (causal) but in most cases people write books roughly in a specific order, because this enforces a narrative, and it’s easier to write a narrative if you already know what’s been previously written.
Similarly, transitive closures on influence follow a specific causal pattern, when taken from root to leaf. We call it a history. Indeed, by the same extension, a transitive closure can be seen as a set of histories with a common originator. Note that this does not necessarily guarantee that two entities in a transitive closure are themselves highly related - the farther back you go to find a common ancestor, the less relevant two nodes are to one another - nor does it imply an ordering of causality outside a specific path.
On the other hand, this does provide a way of determining the degree of contextual relevance - the number of steps in the path between two nodes within a transitive closure provides a (rough) estimate of how contextually related two concepts are, for the closure’s predicate. This last point is important - relevance is contextual. In general, if you are looking for relevance in a transitive closure, you have to use the transitive predicate associated with that closure.
Note that this is a different way of thinking about information than may be the case with an LLM or vector store. Subclass trees, for instance, usually add properties (making the subclass more specific than the superclass) the further you move away from the root node of the closure. Characteristics (or in the case of living beings, genetic sequences) get inherited. In anatomy, you have the “distal to” property which indicates the location of a given bone, nerve or muscle relative to an origin (such as the top of the vertebral column). In effect, each node in such a closure represents a subgraph along the transitive property.
Closures, Bayesians, and Reifications
A Bayesian network is one in which the child nodes of a given node have a probability distribution that adds up to 100%. For instance, the Myers-Briggs classification is a self-describing tool for identifying certain personality types, using four distinct axes - extroversion/introversion (E/I), sensing/intuitive (S/N), thinking/feeling (T/F), and judging/perceiving (J/P). I consider it something akin to D&D Alignment, a rather pseudoscientific classification system that nonetheless can be useful for simulations.
Whether it has any basis in reality, it is a good way to describe Bayesian priors. In this particular case, as you move from the more generally classification (such as Ixxx) to a more specific one, (INxx or ISxx) you can assign population probabilities (known as priors) - thus the population for INxx makes up 75% of the population of Ixxx.
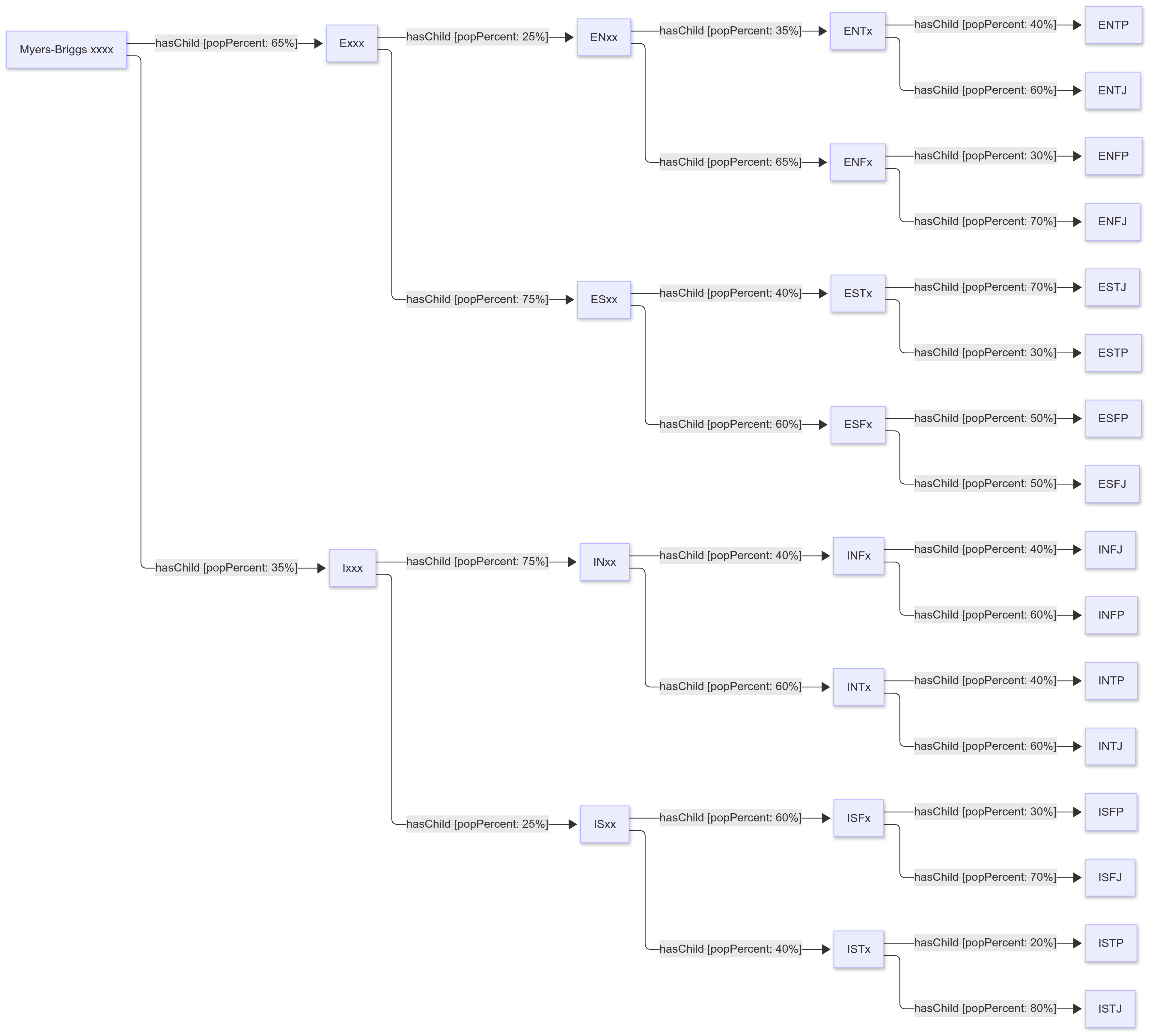
With these priors, you can then determine the total priors for INTP by walking the path back to xxxx (where the x indicates one of two states), and multiplying the priors together. This means that INTPs make up 35% x 75% x 60% x 40% = 6.3% of the total population.
The link from INTx to INTP (with it’s associated prior) can be represented by a reification statement (here in Turtle):
mbti:intx mbti:hasChild mbti:intp.
<<mbti:intx mbti:hasChild mbti:intp>> ex:popPercent 0.40.The notation
<<mbti:intx mbti:hasChild mbti:intp>>gets replaced by a blank node that becomes the subject giving the ex:popPercent property:
mbti:intx mbti:hasChild mbti:intp.
_:reifier ex:popPercent 0.40;
rdf:subject mbti:intx ;
rdf:predicate mbti:hasChild ;
rdf:object mbti:intp ;
.This can be be used to calculate the population for a given node in SPARQL:
select (fn:product(?prior) as ?population where {
values ?targetValue {mbti:intp}
?facet mbti:hasChild+ ?childNode.
?childNode mbti:hasChild* ?targetValue .
<<?facet mbti:hasChild ?childNode>> ex:popPercent ?prior .
}Here fn:product is an extension function for performing the product of all priors in the chain up to the root node.
Recap
Context is a fairly complicated concept, though from a graph standpoint, there is a somewhat simpler (if more limited definition) - if you identify a given node as being $this - where $this is the node of interest - and if $this is part of a transitive closure, then the transitive closure (and the ensuing definition graphs) provides the context for $this. Put another way - let’s say that every node in the transitive closure can be described (there is in fact a describe function in SPARQL that provides a pretty good mechanism for getting the properties associated with the definition for a given node), then the graph consisting of the transitive closure and the associated definitios for each node in that closure provides a good operational definition for a context.
Mind you, this could still potentially mean that the context for $this could be an entire taxonomy, but only if all entities of that taxonomy share a common predicate path (such as subClassOf, or influenced, or narrower term, or whatever that predicate might bw. Arguably, you could even limit the context only to the relevant path to the root node of the transitive closure, based upon the principle of relevance - the longer the chain between two nodes, the less relevant the two nodes are to one another. At that point, it becomes worthwhile to see context as a filter that limits relevancy to keep graph traversal manageable.
This becomes important not only in graph retrievals, but also with large language models, as it suggests that, rather than trying to encode an entire graph, it may make sense only to target the transitive closures within the graph when creating an encoding of that graph. This especially bears fruit when used in conjunction with reification in order to describe the interactions between nodes, which can be thought of as another layer of contextual metadata.
This will be a topic for a future discussion.
In Media Res,

Check out my LinkedIn newsletter, The Cagle Report.
If you want to shoot the breeze or have a cup of virtual coffee, I have a Calendly account at https://calendly.com/theCagleReport. I am available for consulting and full-time work as an ontologist, AI/Knowledge Graph guru, and coffee maker.
I've created a Ko-fi account for voluntary contributions, either one-time or ongoing, or you can subscribe directly to The Ontologist. If you find value in my articles, technical pieces, or general thoughts about work in the 21st century, please contribute something to keep me afloat so I can continue writing.
Thank you for the example from Music! 🙌🏻✨